

Kein Geschwätz… eine direkte, praktische Lösung, die ich erstellt, getestet und die funktioniert hat!
Das Problem!
Wir möchten, dass die Ausgabe eine konsistente JSON-Datei ist, auf die wir uns verlassen können, um damit Tools und Anwendungen zu erstellen!
Lassen Sie mich Ihnen ein Beispiel für ein Tool zeigen, das ich gebaut habe: The Hook Generator Tool
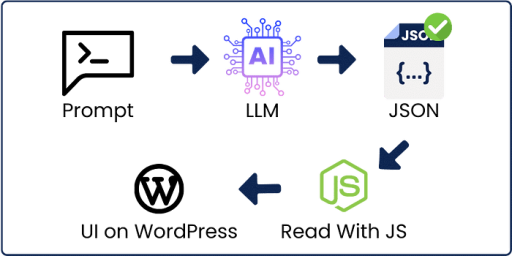
So funktioniert es:
")
Ich erstelle einen Prompt, der Hooks generiert – nicht irgendeinen Prompt, sondern einen Power prompt basierend auf Daten. (nicht unser Thema für heute)
Ich übergebe den Prompt an das Sprachmodell und erhalte eine JSON-Antwort. Dann lese ich die JSON-Datei mit JavaScript und fülle die Benutzeroberfläche auf WordPress aus.
Hier ist eine Beispiel-JSON-Datei, die ich vom LLM für mein Tool erhalten habe:
[
{
"hook_type": "The Intriguing Question",
"hook": "What's the most effective way to learn Python through short videos?"
},
{
"hook_type": "Visual Imagery",
"hook": "Imagine a world where Python tutorials are as captivating as short films."
},
{
"hook_type": "Quotation",
"hook": "Albert Einstein once said, 'The only source of knowledge is experience.' Learn Python through engaging short videos and experience the learning journey."
}
]
Und basierend darauf kann ich eine Benutzeroberfläche wie diese erstellen:
")
🔥 Wenn Sie daran interessiert sind, zu erfahren, wie Sie dieses AI-Tool Schritt für Schritt erstellen und mit dem Guthabensystem monetarisieren können, wie ich es hier auf meiner Website mit meinen Tools tue, um WordPress in eine SaaS-Plattform zu verwandeln, können Sie meine Kurse hier überprüfen. 🔥
Aber lassen Sie uns zu unserem Problem zurückkehren, haben Sie es entdeckt? 🤔
Ja, es befindet sich in der JSON-Datei. Um Tools wie dieses zu erstellen, müssen wir sicherstellen, dass wir jedes Mal die gleiche JSON-Antwort vom Sprachmodell erhalten.
Wenn wir eine andere JSON-Datei erhalten, ist es unmöglich, eine konsistente Benutzeroberfläche für das Tool zu haben, da wir die Antwort nicht mit JavaScript oder einer anderen von Ihnen verwendeten Sprache (selbst ohne Code) parsen und lesen können.
Es gibt mehrere Möglichkeiten und Herangehensweisen, um dieses Problem zu lösen und eine konsistente JSON-Antwort zu erhalten.
Eine Möglichkeit ist die Verwendung von Prompting-Techniken, die das Modell dazu zwingen, eine Antwort basierend auf dem Beispielausgabe zu generieren, die Sie bereitstellen, wie zum Beispiel:
IMPORTANT: The output should be a JSON array of 10 titles without field names. Just the titles! Make Sure the JSON is valid.
Example Output:
[
"Title 1",
"Title 2",
"Title 3",
"Title 4",
"Title 5",
"Title 6",
"Title 7",
"Title 8",
"Title 9",
"Title 10",
]
Eine weitere Möglichkeit ist die Verwendung von Funktionsaufrufen mit OpenAI-Modellen oder der Python Instructor Package mit Pydantic, die jedoch auch auf OpenAI beschränkt ist und auf Funktionsaufrufen beruht.
Ich habe auch den Prozess der Erstellung von AI-Tools schnell für Anfänger in diesem Blog-Beitrag automatisiert und vereinfacht.
Um mehr über dieses Problem und die vorgeschlagenen Lösungen zu erfahren, können Sie diesen Blog-Beitrag lesen, den ich über Funktionsketten geschrieben habe.
Aber was ist mit einem generischen Ansatz, der mit jedem Modell funktioniert und nicht nur auf einer bestimmten Funktionalität beruht?
Sie können nicht alle Ihre Tools und Apps auf Basis einer Funktion oder eines Modells erstellen.
Es ist besser, einen dynamischeren Ansatz zu wählen, damit Sie jederzeit von Modell zu Modell wechseln können, ohne Ihren gesamten Code und Ihre Struktur ändern zu müssen.
Mit diesem Gedanken habe ich eine Methode entwickelt und bin auf einen grundlegenden, aber leistungsstarken Ansatz gekommen, der mir das gewünschte Ergebnis gebracht hat: eine konsistente JSON-Antwort!
Lassen Sie mich Ihnen zeigen, was ich getan habe!
Meine Lösung ✅
Lassen Sie uns die Dinge einfach halten und ein praktisches Beispiel verwenden!
Angenommen, Sie möchten einen einfachen Blog-Titel-Generator erstellen, vielleicht so wie diesen.
Hier ist, was wir brauchen:
- Erstellen Sie einen Prompt, der Blog-Post-Titel generiert.
- Übergeben Sie den Prompt an Google Gemini oder andere Sprachmodelle.
- Erhalten Sie eine JSON-strukturierte Antwort 🔴
- Geben Sie die JSON-Datei an die Benutzeroberfläche zurück, um sie zu erstellen.
Unser Hauptproblem ist Schritt 3.
Hier ist mein Ansatz zur Lösung dieses Problems:
Schritt 1: Entscheiden Sie sich für die JSON-Struktur, die Sie zurückgeben möchten.
Zunächst einmal sollten Sie wissen, was Sie wollen!
Welche JSON-Struktur möchten Sie? Damit Sie das Modell danach fragen können.
Zum Beispiel möchte ich in meinem Fall etwas wie folgt:
{
"titles": [
"Title 1",
"Title 2",
"Title 3",
"Title 4",
"Title 5"
]
}
Jetzt lassen Sie uns ein Python-Skript erstellen und mit Schritt 2 fortfahren.
Schritt 2: Definieren Sie das Modell
Die einfachste und effizienteste Möglichkeit, Tools zu erstellen, besteht darin, eine Klasse oder ein Pydantic-Modell zurückzugeben, das in Ihrem Code einfach gelesen und verwendet werden kann.
Also habe ich ein Pydantic-Modell erstellt, das zur JSON-Antwort passt, die ich möchte.
class TitlesModel(BaseModel):
titles: List[str]
Schritt 3: Erstellen Sie den Basis-Prompt
Jetzt lassen Sie uns einen Prompt erstellen, der Blog-Post-Titel auf Basis eines Themas generiert. Ich werde die Dinge für dieses Beispiel einfach halten und sagen wir mal:
base_prompt = f"Generate 5 Titles for a blog post about the following topic: [{topic}]"
Schritt 4: Konvertieren Sie das Pydantic-Modell in ein JSON-String-Beispiel
Ich habe eine einfache Python-Funktion erstellt, um den Prozess der Erstellung eines JSON-String-Beispiels auf Basis des Pydantic-Modells zu automatisieren.
Wir werden dies verwenden, um es an das LLM in Schritt 5 zu übergeben.
Hier ist die Funktion:
def model_to_json(model_instance):
"""
Converts a Pydantic model instance to a JSON string.
Args:
model_instance (YourModel): An instance of your Pydantic model.
Returns:
str: A JSON string representation of the model.
"""
return model_instance.model_dump_json()
Dann verwenden wir diese Funktion, um die String-Darstellung des Pydantic-Modells zu generieren.
json_model = model_to_json(TitlesModel(titles=['title1', 'title2']))
Schritt 5: Optimieren Sie den Prompt
Jetzt werde ich Prompt Engineering-Techniken verwenden, um das Modell zu zwingen, die JSON-Datei zu generieren, die wir in der Antwort wollen. Hier ist, wie ich es gemacht habe:
optimized_prompt = base_prompt + f'.Please provide a response in a structured JSON format that matches the following model: {json_model}'
Es geht einfach darum, dem Sprachmodell zu sagen, eine JSON-Datei zu generieren, die dem JSON-Modell entspricht, das wir in Schritt 4 generiert haben.
Schritt 6: Generieren Sie die Antwort mit Gemini
Rufen Sie jetzt die Gemini-API auf und generieren Sie eine Antwort mit dem optimized_prompt.
Ich habe eine einfache Funktion erstellt, die dies tut, damit ich sie direkt in meinem Code verwenden kann. Hier ist es:
import google.generativeai as genai
# Configure the GEMINI LLM
genai.configure(api_key='AIzgxb0')
model = genai.GenerativeModel('gemini-pro')
#basic generation
def generate_text(prompt):
response = model.generate_content(prompt)
return response.text
Dann rufe ich es aus meinem Skript auf:
gemeni_response = generate_text(optimized_prompt)
Dann erhalten wir etwas wie:
Absolutely! Here's a JSON format representation of 5 engaging blog post titles for a Python programming blog:
JSON
{
"titles": [
"Python Tricks: 5 Hidden Gems You Might Have Missed",
"Mastering Python Data Structures: Level Up Your Coding",
"Debugging Python Code Like a Pro: Strategies and Tools",
"Project Inspiration: Build a Fun Web App with Python",
"Elegant Python: Writing Clean and Readable Code"
]
}
Eine Kombination aus Text und JSON in der Antwort!
Aber die JSON-Datei ist so konstruiert, wie wir es wollen, großartig!
Schritt 7: Extrahieren Sie die JSON-String-Datei
Jetzt habe ich reguläre Ausdrücke verwendet, um den JSON-String aus der Ausgabe zu extrahieren.
Hier ist die Funktion, die ich erstellt habe:
def extract_json(text_response):
# This pattern matches a string that starts with '{' and ends with '}'
pattern = r'\{[^{}]*\}'
matches = re.finditer(pattern, text_response)
json_objects = []
for match in matches:
json_str = match.group(0)
try:
# Validate if the extracted string is valid JSON
json_obj = json.loads(json_str)
json_objects.append(json_obj)
except json.JSONDecodeError:
# Extend the search for nested structures
extended_json_str = extend_search(text_response, match.span())
try:
json_obj = json.loads(extended_json_str)
json_objects.append(json_obj)
except json.JSONDecodeError:
# Handle cases where the extraction is not valid JSON
continue
if json_objects:
return json_objects
else:
return None # Or handle this case as you prefer
def extend_search(text, span):
# Extend the search to try to capture nested structures
start, end = span
nest_count = 0
for i in range(start, len(text)):
if text[i] == '{':
nest_count += 1
elif text[i] == '}':
nest_count -= 1
if nest_count == 0:
return text[start:i+1]
return text[start:end]
Dann rufe ich es auf:
json_objects = extract_json(gemeni_response)
Jetzt haben wir die JSON-Datei!
Schritt 8: Validieren Sie die JSON-Datei
Bevor Sie die JSON-Datei verwenden, habe ich sie validiert, um sicherzustellen, dass sie mit dem Pydantic-Modell übereinstimmt, das ich wollte. Dies ermöglicht mir auch, eine erneute Anfrage zu implementieren, falls Fehler auftreten.
Hier ist die Funktion, die ich erstellt habe:
def validate_json_with_model(model_class, json_data):
"""
Validates JSON data against a specified Pydantic model.
Args:
model_class (BaseModel): The Pydantic model class to validate against.
json_data (dict or list): JSON data to validate. Can be a dict for a single JSON object,
or a list for multiple JSON objects.
Returns:
list: A list of validated JSON objects that match the Pydantic model.
list: A list of errors for JSON objects that do not match the model.
"""
validated_data = []
validation_errors = []
if isinstance(json_data, list):
for item in json_data:
try:
model_instance = model_class(**item)
validated_data.append(model_instance.dict())
except ValidationError as e:
validation_errors.append({"error": str(e), "data": item})
elif isinstance(json_data, dict):
try:
model_instance = model_class(**json_data)
validated_data.append(model_instance.dict())
except ValidationError as e:
validation_errors.append({"error": str(e), "data": json_data})
else:
raise ValueError("Invalid JSON data type. Expected dict or list.")
return validated_data, validation_errors
Hier ist, wie ich es in meinem Code verwendet habe:
validated, errors = validate_json_with_model(TitlesModel, json_objects)
Schritt 9: Arbeiten Sie mit dem Modell!
Wenn es keine Fehler aus Schritt 8 gibt, können wir die JSON-Datei erneut in Pydantic konvertieren und damit arbeiten, wie wir möchten!
Hier ist die Funktion, die JSON erneut in Pydantic konvertiert:
def json_to_pydantic(model_class, json_data):
try:
model_instance = model_class(**json_data)
return model_instance
except ValidationError as e:
print("Validation error:", e)
return None
Hier ist, wie ich es in meinem Skript verwendet habe:
model_object = json_to_pydantic(TitlesModel, json_objects[0])
#play with
for title in model_object.titles:
print(title)
Sie sehen, jetzt kann ich einfach auf die Titel in meinem Code zugreifen!
Holen Sie sich den vollständigen Code
Mein magischer Ansatz!
Statt jedes Mal alle Schritte zu durchlaufen, wenn Sie ein Tool erstellen oder ein Skript schreiben möchten, habe ich alle Schritte als eine einzige Funktion in der SimplerLLM Library hinzugefügt!
Hier ist, wie Sie den gleichen Blog-Titel-Generator mit SimplerLLM mit nur wenigen Zeilen Code erstellen können:
from pydantic import BaseModel
from typing import List
from SimplerLLM.langauge.llm import LLM, LLMProvider
from SimplerLLM.langauge.llm_addons import generate_basic_pydantic_json_model as gen_json
llm_instance = LLM.create(provider=LLMProvider.GEMINI, model_name="gemini-pro")
class Titles(BaseModel):
list: List[str]
topic: str
input_prompt = "Generate 5 catchy blog titles for a post about SEO"
json_response = gen_json(model_class=Titles,prompt=input_prompt, llm_instance=llm_instance)
print(json_response.list[0])
Alle Schritte sind jetzt in einer einzigen Zeile komprimiert:
json_response = gen_json(model_class=Titles,prompt=input_prompt, llm_instance=gemini)
Auf diese Weise können Sie AI-Tools viel schneller erstellen und sich auf die Tool-Idee, die Funktionalität und den Prompt konzentrieren, anstatt sich mit inkonsistenten JSON-Dateien herumzuschlagen.
Was noch wichtiger ist, ist, dass Sie mit diesem Ansatz nicht auf ein bestimmtes Sprachmodell beschränkt sind. Zum Beispiel können Sie diese Zeile:
llm_instance = LLM.create(provider=LLMProvider.GEMINI, model_name="gemini-pro")
In diese Zeile ändern:
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4")
Und Sie werden ein anderes Modell verwenden… Es ist wirklich wie Magie, oder?
Ich würde mich sehr freuen, wenn Sie mir Ihre Gedanken und Meinungen mitteilen und vielleicht Ihre Testergebnisse, wenn Sie welche durchführen.
Ich denke, ich verdiene einige Klatscher 😅


