OCR (Optical Character Recognition) ist eine beherrschte Wissenschaft und das schon seit einiger Zeit. Das Problem heutzutage liegt in der Extraktion und Verarbeitung der Daten, und hier zeigt LLM (Large Language Model) seine Stärken. JPMorgan hat kürzlich DocLLM [1] vorgestellt, ein LLM, das speziell für diesen Zweck entwickelt wurde. Das Modell ist noch nicht verfügbar und weist einige Einschränkungen hinsichtlich der Kontextfenstergröße auf. Deshalb habe ich mich entschieden, das Gegenteil zu tun: eine vollständig quelloffene Lösung mit einer viel größeren Fenstergröße.
Das Repository finden Sie hier:
https://github.com/enoch3712/Open-DocLLM
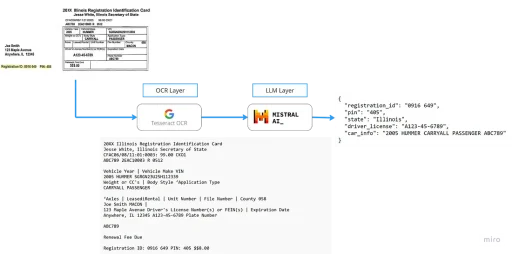
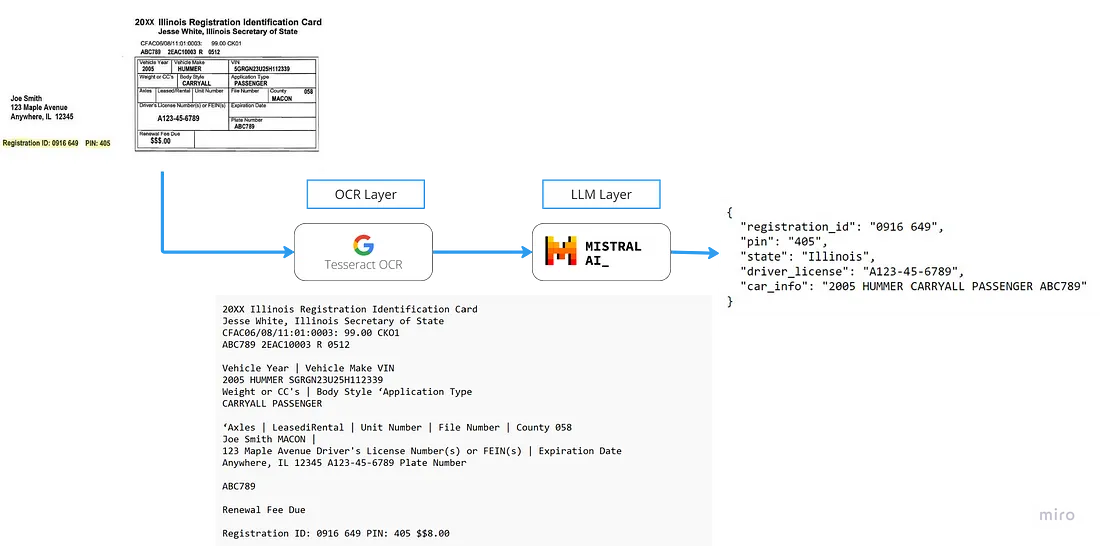
Das Projekt ist in zwei Teile gegliedert: die OCR- und die LLM-Schicht. In produktionsreifen Projekten wären dies separate Microservices oder sogar separate Dienste. Aber die Aufteilung ist klar: es gibt das Lesen des gesamten Inhalts (OCR-Schicht) und dann die Extraktion der spezifischen Inhalte (LLM-Schicht).
OCR-Schicht

Seiten in Bilder umwandeln
Zunächst ist es wichtig, Dateien jeglichen Typs in Bilder umzuwandeln. Dieser Ansatz stellt sicher, dass der gesamte Inhalt des Dokuments zugänglich ist. Durch die Aufteilung der Seiten in Einzelbilder können diese in den nachfolgenden Schritten einzeln verarbeitet werden.
Vorverarbeitung des Bildes für OCR
Oft sind Bilder von schlechter Qualität und erfordern Anpassungen, um die Lesbarkeit zu verbessern. Verbesserungen können Kontraständerungen sowie die Verwendung verschiedener Bibliotheken und Frameworks beinhalten. In diesem Artikel werden wir nicht näher auf diese Details eingehen, aber die Implementierung solcher Anpassungen ist für Produktions-Anwendungsfälle unerlässlich.
Tesseract OCR
Dies ist das bekannteste und beliebteste Open-Source-OCR (https://github.com/tesseract-ocr/tesseract) der Welt. Es ist auch recht alt, wurde aber im Laufe der Zeit verbessert, um mehr Sprachstrukturen und Tabellen zu unterstützen. Dieses Beispiel unterstützt Tabellen, indem sie durch „|“ getrennt werden.
Es verwendet pytesseract (https://github.com/madmaze/pytesseract), um über Python eine Verbindung zu Tesseract herzustellen. Hier ist der Code:
def extract_text_with_pytesseract(list_dict_final_images):
image_list = [list(data.values())[0] for data in list_dict_final_images]
image_content = []
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = []
for index, image_bytes in enumerate(image_list):
future = executor.submit(process_image, index, image_bytes)
futures.append(future)
for future in concurrent.futures.as_completed(futures):
try:
raw_text = future.result()
image_content.append(raw_text)
except Exception as e:
raise Exception(f"Error processing image: {e}")
return image_content
# nur diese Funktion ist wichtig, der Rest ist Concurrent-Logik
def process_image(index, image_bytes):
try:
image = Image.open(BytesIO(image_bytes))
raw_text = str(image_to_string(image))
return raw_text
except Exception as e:
raise Exception(f"Error processing image {index}: {e}")
Ignorieren Sie den größten Teil des Codes in der Funktion extract_text_with_pytesseract, da es sich hauptsächlich um Concurrent-Logik handelt, damit Sie gegebenenfalls parallel verarbeiten können.
LLM-Schicht
Definition des Extraktionsvertrags
Nachdem wir den Inhalt des Dokuments haben, müssen wir die Informationen strukturiert extrahieren. Das folgende Bild zeigt den vollständigen Prompt:

Der Protokoll-Abschnitt kann auf verschiedene Arten definiert werden, aber Sie sollten etwas Ähnliches oder sogar dasselbe wie bei einer Programmiersprache verwenden. Dieses Protokoll hier ist ein Pseudo-Code, der den Namen, den Typ und die Beschreibung des Felds enthält.
Sie können auch die Klassifizierung von Dokumenten anfordern:
documentType:string => kann nur "invoice", "bill of sale", "LLC creation document", "Eviction Document" sein
Warum haben wir JSON anstelle anderer Formate wie YAML gewählt, insbesondere wenn YAML oft zu kleineren Payloads führt? Die Antwort liegt in der Verfügbarkeit von Trainingsdaten. JSON ist in den Datensätzen, die für das Training verwendet werden, weitaus häufiger vertreten, da es das primäre Datenaustauschdatenformat im Web ist.
Korrekte JSON-Extraktion
In OpenAI können Sie bereits den JSON-Rückgabetyp verwenden:
response = openai.Completion.create(
model="text-davinci-003",
prompt="Translate the following English text to French: 'Hello, how are you?'",
response_format={ "type": "json_object" }
)
Da diese Funktionalität hier nicht verfügbar ist, müssen Sie die JSON-Struktur manuell hinzufügen und dann kürzen. In der Regel werden die Ergebnisse in diesem Format für Trainingszwecke zurückgegeben:
[Content]
Mit diesem Verständnis können wir wie folgt mit dem Eingabeinhalt vorgehen:
{
"model": "mistral-tiny",
"messages": [
{
"role": "user",
"content": "[Content]```json\n{"
}
],
...
}
Dies führt zum folgenden Ausgabeinhalt:
{
...
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "[Content]```[Content]"
},
"finish_reason": "stop"
}
],
...
}
Sie können diese Funktion verwenden, die sowohl die Inhalte erhält als auch das extrahierte JSON zurückgibt:
def extractJsonSubstring(str1, str2):
# Verketten der beiden Strings
combined_str = str1 + str2
# Definition der Start- und End-Marker
start_marker = "```json"
end_marker = "```"
# Finden der Start- und End-Positionen des Substrings
start_pos = combined_str.find(start_marker)
### start_pos um die Länge des Start-Markers verschieben
start_pos = start_pos + len(start_marker)
end_pos = combined_str.find(end_marker, start_pos)
# Substring extrahieren
json_substring = combined_str[start_pos:end_pos]
return json_substring
Lokal ausführen — OLLAMA
Es gibt heutzutage mehrere Möglichkeiten, Modelle lokal auszuführen, wie LLM Studio oder Ollama. In diesem Fall können Sie aufgrund des Projekts LlamaIndex und Ollama (https://blog.llamaindex.ai/running-mixtral-8×7-locally-with-llamaindex-e6cebeabe0ab) verwenden. Dieser Artikel deckt alles ab, sodass Sie den API-Aufruf entfernen und die gleiche Erfahrung für eine lokale On-Premises-Lösung haben können.
Werfen Sie einen Blick auf den Code und testen Sie ihn
In diesem Repository (https://github.com/enoch3712/Open-DocLLM) finden Sie eine FastAPI-App mit einem Endpunkt, um all diese Komponenten zu testen. Es handelt sich jedoch um eine einfache API, die Sie für Ihren spezifischen Anwendungsfall erweitern sollten.
Zuerst sollten Sie auf die richtige Tesseract-Executable zeigen:

Wenn Sie Docker verwenden, verwenden Sie die zweite Option und kommentieren Sie den hartcodierten Pfad aus.
Außerdem verwendet dieses Beispiel eine direkte Anfrage an die Mistral-API. Stellen Sie sicher, dass Sie den Schlüssel in der config.py-Datei geändert haben.

Dies ist ein FastAPI-Projekt, stellen Sie also sicher, dass Sie die Abhängigkeiten installieren und zu localhost:8000/docs gehen.
Gehen Sie dann zum Endpunkt /extract mit der Datei und dem Vertrag.

Senden Sie die Anfrage ab und Sie sollten das richtige Ergebnis erhalten. Beachten Sie, dass dies nur eine Vorlage ist und einige Dinge möglicherweise nicht mit komplexeren Verträgen funktionieren.

Fortgeschrittene Fälle: 1 Million Token Kontext
LLMLingua

LLMLingua (https://github.com/microsoft/LLMLingua~) [2] ist eine meiner Lieblingssoftware, die ich seit einiger Zeit gesehen habe. Es ist clever und einfach, indem ein viel kleineres Modell feinabgestimmt wird, um den Inhalt zu komprimieren, sodass er an ein viel größeres, teureres Modell übergeben werden kann.
Laut dem Paper gibt es bei einer 20-fachen Kompression einen Leistungsabfall von ca. 1,5 %, was aber von der Art der Daten abhängt.
Mistral Yarn 128k Kontextfenster
YaRN (Yet another RoPE extensioN method) (https://github.com/jquesnelle/yarn) [3] verwendet Rotary Position Embeddings (RoPE), um die Fenstergröße zu erhöhen. Sie können mehr in dem Paper lesen, aber es ermöglicht Ihnen, die Fenstergröße mit nahezu keinem Verlust zu vergrößern. Sie können es hier (https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) testen.
Durch die Kombination beider Techniken mit einer 10x * 128k Kontextfenster-Kompressionsrate erhalten Sie eine Fenstergröße von über 1 Million. Sie können eine ganze Bibel unterbringen!
Anwendungsfälle für größere Kontexte
Manchmal enthält eine Seite nicht alle Werte, die extrahiert werden sollen, manchmal sind es mehrere Seiten. Das Erfassen der Daten und anschließende Aggregieren kann ein Problem darstellen, da falsche Werte anstelle von null extrahiert werden könnten (wie im Abschnitt zum Vertrag besprochen). Eine Lösung könnte daher einfach sein, den Kontextinhalt zu vergrößern, damit nichts außen vor bleibt.
Dies wäre ein extremer Anwendungsfall, seien Sie also vorsichtig, wie Sie ihn nutzen möchten.
Fazit
Die Integration von OCR- und LLM-Technologien, wie sie in dem Open-Source-Projekt für die Dokumentenextraktion gezeigt wird, markiert einen entscheidenden Fortschritt bei der Analyse unstrukturierter Daten. Die Kombination von Open-Source-Projekten wie Tesseract und Mistral ergibt eine perfekte Implementierung, die in einem On-Premises-Anwendungsfall verwendet werden könnte.
Referenzen & Dokumente
[1] DOCLLM: A LAYOUT-AWARE GENERATIVE LANGUAGE MODEL FOR MULTIMODAL DOCUMENT UNDERSTANDING: https://arxiv.org/pdf/2401.00908.pdf
[2] LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models: https://arxiv.org/pdf/2310.05736.pdf
[3] YaRN: Efficient Context Window Extension of Large Language Models: https://arxiv.org/pdf/2309.00071.pdf