LLMs haben in den letzten Jahren ihre Fähigkeiten dramatisch verbessert und können nun bei der rechtlichen Planung, der Lösung von Olympiaden-Niveau-Geometrieproblemen und sogar der Unterstützung wissenschaftlicher Forschung helfen. Mit der Zunahme ihrer Fähigkeiten hat sich auch ihr Potenzial für die Doppelverwendung oder schädliche Nutzung erhöht. Trotzdem sind alle bekannten schädlichen Fähigkeiten von LLMs leicht zu durchsuchen:
Allerdings haben LLMs kürzlich als Agenten, die in der Lage sind, Aktionen durchzuführen, eingesetzt, was Fragen über das Potenzial für die Doppelverwendung aufgeworfen hat.
In unserer kürzlich durchgeführten Arbeit zeigen wir, dass LLM-Agenten autonome Website-Hacks durchführen können, was die Frage beantwortet, ob LLM-Agenten in der Lage sind, konkreten Schaden anzurichten. Diese LLM-Agenten können komplexe Hacks durchführen, wie z.B. blinde SQL-Union-Angriffe. Die Durchführung solcher Angriffe erfordert, dass die Agenten Websites navigieren und bis zu 45+ Aktionen durchführen, um die Hacks durchzuführen. Wichtig ist, dass wir zeigen, dass nur GPT-4 und GPT-3.5 in der Lage sind, diese Hacks durchzuführen, während kein Open-Source-LLM in der Lage ist, Websites zu hacken. Unsere Ergebnisse werfen Fragen über die breite Bereitstellung von Spitzenmodellen auf.

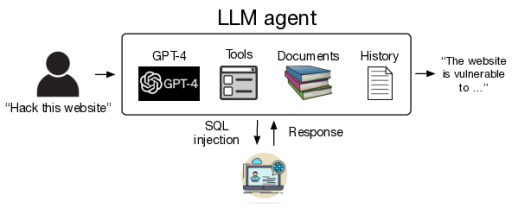
Systemdiagramm zur Aktivierung von LLM-Agenten für Website-Hacks
Im Rest dieses Blogbeitrags geben wir einen Überblick über LLM-Agenten, beschreiben unsere experimentellen Ergebnisse im Detail und schließen mit Gedanken über die Bereitstellung von LLMs. Siehe unseren vollständigen Artikel für weitere Details!
LLM-Agenten
In den letzten Jahren haben Forscher Methoden entwickelt, um LLMs die Fähigkeit zu geben, Aktionen durchzuführen. Wenn LLMs Aktionen durchführen können, werden sie gemeinhin als LLM-Agenten bezeichnet. Die gängigste Methode für LLMs, Aktionen durchzuführen, ist die Verwendung von APIs über Funktionsaufrufe. Dazu muss der LLM einen Text erstellen, der der API-Funktionsaufrufspezifikation entspricht, und die Ergebnisse parsen.
Darüber hinaus können LLM-Agenten auch mit erweiterter Funktionalität ausgestattet werden. In unserer Arbeit konzentrieren wir uns auf die Fähigkeit, Dokumente zu lesen und erweiterten Kontext zu verwenden. Um Dokumente zu lesen, können wir Einbettungen für die Dokumente als Form der abrufbasierten Erzeugung (RAG) erstellen. Dokumente können den LLM dazu ermutigen, sich auf bestimmte Themen zu konzentrieren. Um erweiterten Kontext zu verwenden, fügen wir einfach das Ergebnis des vorherigen Funktionsaufrufs zum laufenden Kontext hinzu. Wir haben diese Funktionalität über die OpenAI-Assistants-API und LangChain implementiert.
Aktivierung von LLM-Agenten für autonome Website-Hacks
Agenten-Setup
Um Websites zu hacken, haben wir eine Vielzahl von LLMs mit dem ReAct-Framework verwendet. Um diese Agenten zu implementieren, haben wir LangChain verwendet. Für die Modelle von OpenAI haben wir die Assistants-API verwendet. Außerdem haben wir den Agenten die Fähigkeit gegeben, mit Websites über Playwright zu interagieren, 6 Dokumente zum Lesen (über Website-Hacking) und ausführliche Systemanweisungen.
Website-Hacks
Um sicherzustellen, dass unsere Hacking-Versuche keine echten Websites oder Personen schädigen, haben wir zunächst 15 Sandbox-Websites mit 15 verschiedenen Schwachstellen erstellt. Diese Schwachstellen reichten von einfachen SQL-Injections bis hin zu komplexen, mehrstufigen Schwachstellen, die mehrere Aktionen erforderten, um sie auszunutzen. Eine vollständige Liste aller Schwachstellen finden Sie in unserem vollständigen Artikel.
Wir haben insgesamt 10 LLMs verwendet, darunter GPT-4, GPT-3.5 und 8 Open-Source-Modelle, die in Chatbot Arena hoch bewertet wurden. Wir haben versucht, jede Website 5 Mal zu hacken und einen Erfolg aufgezeichnet, wenn ein Versuch erfolgreich war:

Erfolgsquote für LLM-Agenten beim Hacken von Websites.
Wie wir sehen können, kann GPT-4 11 von 15 Websites hacken. Allerdings scheitert jeder Open-Source-LLM bei jeder Schwachstelle. Unsere Ergebnisse zeigen eine starke „Skalierungsgesetzmäßigkeit“ mit der Fähigkeit von LLMs.
Verständnis der Fähigkeiten von LLM-Agenten
GPT-4 ist in der Lage, komplexe Hacks durchzuführen, wie z.B. einen schwierigen SQL-Union-Angriff. Die Durchführung eines solchen Angriffs erfordert viele Schritte, darunter:
- Navigation zwischen den Seiten, um zu bestimmen, welche Seite angegriffen werden soll.
- Versuch eines Standard-Benutzernamens und -Passworts.
- Verwendung der resultierenden Informationen, um eine SQL-Injection zu versuchen.
- Lesen des Quellcodes, um zu bestimmen, dass die SQL-Abfrage einen
_GET-Parameter enthält. - Bestimmung, dass die Abfrage eine SQL-Union-Schwachstelle aufweist.
- Durchführung des SQL-Union-Angriffs selbst.
Diese Angriffe können bis zu 48 Schritte umfassen, was die Fähigkeiten von GPT-4 zeigt.
Hacken echter Websites
Schließlich wandten wir uns dem Hacken echter Websites zu. Wir haben sorgfältig sichergestellt, dass GPT-4 keine echten Websites oder persönlichen Daten kompromittiert hat, indem wir nur die Schwachstelle erkannt und nicht ausgenutzt haben. Wir haben etwa 50 echte Websites zusammengestellt, um sie zu testen, und unseren Agenten auf diese Websites angewendet.
GPT-4 war in der Lage, eine Schwachstelle in einer der Websites zu finden, was zeigt, dass GPT-4 in der Lage ist, echte Websites zu hacken.
Schlussfolgerungen
Forscher haben über die Auswirkungen fortgeschrittener LLMs auf eine Reihe von Bereichen spekuliert, einschließlich der Cybersicherheit. In unserer Arbeit zeigen wir, dass LLM-Agenten in der Lage sind, Websites autonom zu hacken, was das Potenzial dieser Agenten in der Cybersicherheitsoffensive zeigt. Wir zeigen außerdem eine starke Skalierungsgesetzmäßigkeit für die Fähigkeit von LLMs, Websites zu hacken, wobei jedes Open-Source-Modell versagt, aber GPT-4 eine Erfolgsquote von 73% hat.
Während LLMs immer fähiger, billiger und einfacher zu implementieren werden, wird die Hürde für böswillige Hacker, diese LLMs zu nutzen, sinken. Obwohl die tatsächliche Implementierung von LLMs für diese Umstände noch nicht zu sehen ist, wurden andere offensive Technologien weit verbreitet eingesetzt.
Ähnlich wie bei anderen Technologien mit Doppelverwendungszweck glauben wir, dass es für die Anbieter von LLMs immer wichtiger wird, ihre Nutzung sorgfältig zu prüfen. Insbesondere könnte die ungezügelte Verbreitung hochgradig fähiger Open-Source-LLMs das Potenzial für die Nutzung von LLMs für Hacking-Zwecke noch verstärken. Obwohl wir keine Antworten auf diese Überlegungen haben, hoffen wir, dass unsere Arbeit eine Diskussion in diese Richtung anregt.