Einführung
Es war ein langer Weg, um hierher zu gelangen. Ich arbeite seit Oktober 2021 (OpenAI Codex) mit LLMs und begann sofort mit der Extraktion. Ich versuchte, in .NET eine ähnliche Lösung wie die hier vorgestellte zu entwickeln, aber eine herstellerunabhängige Lösung war nicht einfach, vor allem ohne Zugriff auf die nützlichen Tools, die in Python verfügbar sind.
Ich habe über einen Monat damit verbracht, den gesamten Code, den Sie in diesem GitHub-Repository sehen, zu migrieren. Dies ist die erste Version, mehr ein Proof of Concept als alles andere, das im Laufe der Zeit erweitert und hoffentlich so viel Anklang finden wird wie LiteLLM oder instructor.
Motivation
Wenn Sie Dokumentenextraktion mit LLMs verwenden, werden Ihnen manchmal Fragen dieser Art gestellt:
„Kann ich diese Gruppe von Dateien nach dieser Klassifizierung trennen?“
„Können wir einfach diese Felder hier extrahieren? Ich möchte ein anderes Format.“
„Können wir sie klassifizieren und ein Stück Information extrahieren?“
Sie haben bereits mehrere Tools, um dies zu erreichen, wie AWS Textract oder Azure AI Document Intelligence, mit denen Sie dies mit etwas Codierarbeit auf Ihrer Seite erledigen können. Sie bieten eine Reihe von Vorlagen und ein Trainingsökosystem, damit Sie Ihren Dokumententyp hinzufügen können, und es ist wichtig zu erwähnen, dass sie auch Transformer-Modelle sind. Das große Problem sind normalerweise die Anbindung an einen bestimmten Anbieter und die Entwicklungskosten für das Training des Modells.
Lassen Sie uns die Kosten einer Lösung mit Azure Document Intelligence und einer Alternative mit LLMs und auch Azure Document Intelligence vergleichen. Ich werde diese Preistabelle von Azure verwenden.

Azure bietet Ihnen einen einfachen „Lese“-Dokumententyp für die Extraktion, der ohne Felder oder Geschäftslogik extrahiert. Das ist gut genug, um eine Struktur wie Absätze, Kontrollkästchen und Tabellen zu erhalten, und das reicht aus, um mit GPT 3.5 zu arbeiten. Die restlichen Cloud-Anbieter haben ähnliche Dienste mit ähnlichen Preisen, sodass die Rechnung die gleiche sein sollte.
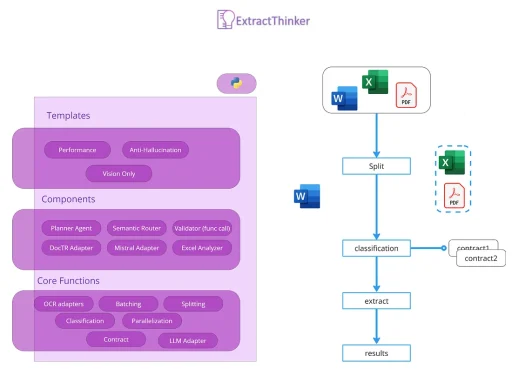
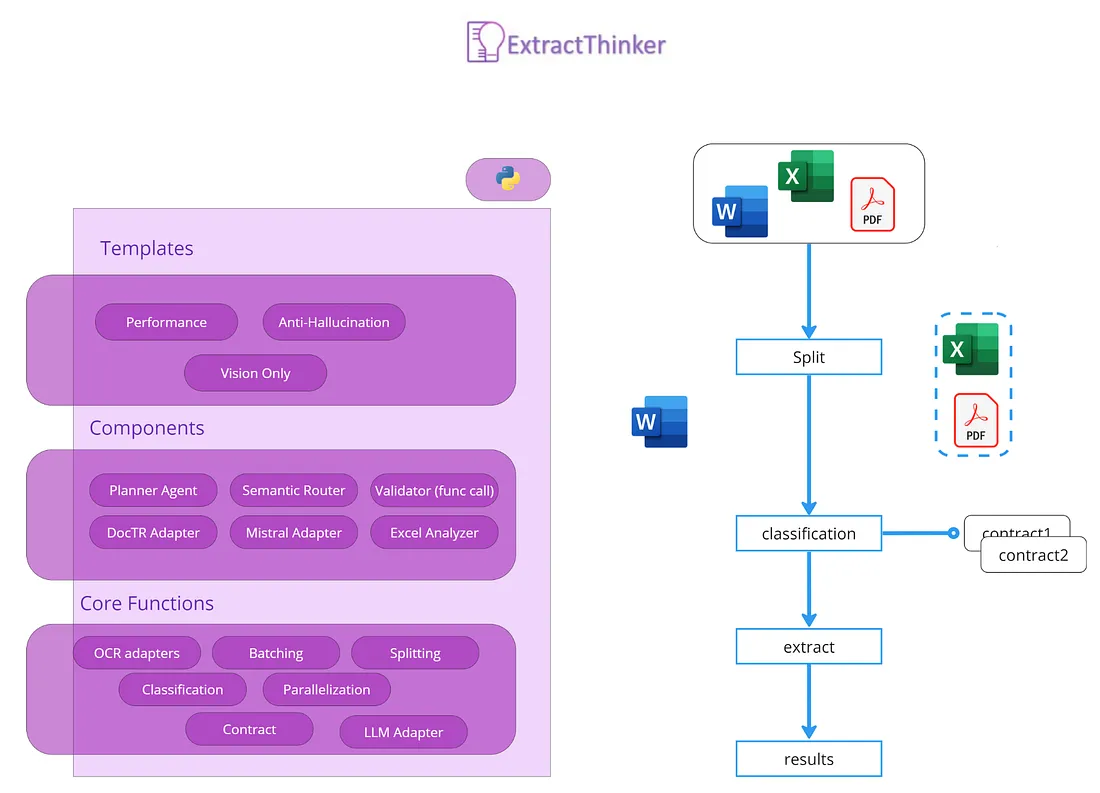
Außerdem sind diese Tools nicht auf ein normales Domänenmodell ausgerichtet, sodass Sie eine Menge Mapping machen müssen, ähnlich wie wenn Sie SQL-Ergebnisse in eine Klasse in einer OOP-Sprache konvertieren. Am besten betrachtet man dieses Projekt also als eine Art „ORM für die Dokumentenextraktion“. Das folgende Bild drückt diese Idee gut aus:

In einem traditionellen ORM kümmert sich ein Datenbanktreiber um die Zuordnung von Datenbanktabellen zu Klassen. ExtractThinker verwendet in ähnlicher Weise OCR und LLM als „Treiber“, um Dokumentenfelder den Klassenattributen zuzuordnen. Diese ORM-ähnliche Interaktion vereinfacht den Prozess und wandelt unstrukturierte Dokumentendaten in strukturierte um.
Funktionen
Hinsichtlich des Projektziels und der Größe sollten Sie es mit LiteLLM und instructor vergleichen. Sie lösen einen spezifischen Anwendungsfall, wie die Erstellung eines Lastausgleichs für mehrere LLMs oder die Gewährleistung, dass die Ausgabe in pydantic geparst wird. Dieses Projekt lässt sich davon inspirieren und verlässt sich vorerst stark darauf. Das folgende Bild zeigt eine gute Möglichkeit, wie man über dieses Projekt denken kann.

Das Projekt wird in den Bereich der „Document Intelligence“ vordringen und einen Mapper für Textract oder Azure DI anbieten, der mit einem kostengünstigen LLM gepaart werden kann. Außerdem können fortschrittlichere Tools wie Anti-Halluzination und ToT in die Pipeline aufgenommen werden, um die Qualität der Ergebnisse zu erhöhen.
Hier ist eine Liste der Funktionen, die Sie erwarten können:
- Unterstützung mehrerer Dokumentenlader, darunter Tesseract OCR, Azure Form Recognizer, AWS Textract und Google Document AI.
- Anpassbare Extraktion mit Vertragsdefinitionen.
- Asynchrone Verarbeitung für effiziente Dokumentenbearbeitung.
- Integrierte Unterstützung für verschiedene Dokumentformate.
- ORM-ähnliche Interaktion zwischen Dateien und LLMs.
Codebeispiel
from extract_thinker import DocumentLoaderTesseract, Extractor, Contract
# Vertragsdefinition. Basierend auf instructor/pydantic
class InvoiceContract(Contract):
invoice_number: str
invoice_date: str
path = "some\path"
# Erstellung des Extraktors
extractor = Extractor()
# Laden des Dokumentenladers. In diesem Fall Tesseract
extractor.load_document_loader(
DocumentLoaderTesseract(tesseract_path)
)
# Laden des LLM-Modells. Verwendet LiteLLM für die Hauptaufgabe
extractor.load_llm("claude-3-haiku-20240307")
# Extrahieren der Daten mit dem obigen Vertrag
result = extractor.extract(path, InvoiceContract)
print("Rechnungsnummer: ", result.invoice_number)
print("Rechnungsdatum: ", result.invoice_date)
Warum nicht einfach LangChain?
Während LangChain ein generalisierter Rahmen ist, der für eine breite Palette von Anwendungsfällen konzipiert ist, konzentriert sich extract_thinker speziell auf die Intelligente Dokumentenverarbeitung (IDP). Das ist der Unterschied, und LangChain ist bei der Extraktion begrenzt, obwohl sie sie jetzt zu einem Kernbestandteil ihres Produkts machen. Mehr dazu finden Sie in diesem GitHub-Repository.
Von diesem Projekt sollten eine Gruppe fertiggestellter und getesteter Templates basierend auf Ihrem Anwendungsfall oder zumindest nah daran erwartet werden. Dieser Grund allein rechtfertigt die Existenz dieses Projekts, und so sollten Sie es sehen: eine Sammlung von Tools für Document Intelligence mit Hilfe von LLMs.
Im Vergleich zu LangChain ist die Struktur ziemlich ähnlich, unterteilt in:
Kern: Drittanbieter-Projekte wie LiteLLM und Instructor sowie andere interne wie DocumentLoader, Cache, Klassifizierung und abstrakte Splittcode.
Komponenten: Implementierung des DocumentLoaders für die unterstützten OCRs (z.B. DocumentLoaderTesseract), Image-Splitting, Unterstützung für LLMs und so weiter.
Vorlagen: Eine Gruppe von Vorlagen, die out-of-the-box funktionieren, eine Kombination aus mehreren Komponenten, um einen Anwendungsfall zu erfüllen.
HINWEIS: Dies wird sich wahrscheinlich bald ändern, da es sich erst um die erste Version handelt. Stellen Sie sicher, dass Sie die offizielle Dokumentation überprüfen.
Anwendungsfälle
- Verschiedene Gruppen von Dokumenten in einer PDF-Datei
- Herstellerunabhängige KI-Dokumentenerkennung
- Extraktion aus mehreren Dokumentenquellen
- Klassifizierung (Mischung aus Modellen)
- Herstellerunabhängige Klassifizierung von Formularen durch Bildvergleich
- Extrahieren von Daten „geparst“ in eine andere Sprache
Weitere Beispiele werden der Dokumentation und diesem Medium-Konto hinzugefügt.
Fazit
ExtractThinker ist eine Bibliothek, die Document Intelligence für LLMs bringen soll. Sie basiert auf einem vorherigen .NET-Projekt, das in Python migriert und implementiert wurde. ExtractThinker verwendet einen ORM-ähnlichen Ansatz für die Dokumentenextraktion und kombiniert OCR mit LLMs für Leistung und herstellerunabhängige Nutzbarkeit.
Es wird erwartet, dass das Projekt im Laufe seiner Entwicklung eine vielfältige Sammlung fertiger und getesteter Vorlagen für unterschiedliche Anwendungsfälle anbieten wird, wodurch seine Position als wichtige Ressource für Document Intelligence mit LLMs weiter gestärkt wird.
Tragen Sie gerne zu dem Projekt bei, das immer Open Source bleiben wird. Und wenn möglich, geben Sie ihm einen ⭐!
[1] Ziwei X., Sanjay J., Mohan K.“Hallucination is Inevitable: An Innate Limitation of Large Language Models“ (2024), arXiv