Ich bin ein Fan von kleinen Sprachmodellen, hauptsächlich weil ich keine leistungsstarke GPU besitze und somit in meiner Hardware eingeschränkt bin.
Aber was wäre, wenn es eine Möglichkeit gäbe, ein wirklich riesiges Sprachmodell kostenlos zu testen? Ich meine, ein Modell mit 14B, 32B oder sogar 110 Milliarden Parametern zu betreiben, würde eine Super-Hardware erfordern oder eine kostenpflichtige Abonnement für Tokens.
Ich habe zufällig herausgefunden, dass es einen geheimen Trick gibt, um dies zu tun.
Ich bin nicht dagegen, für Ressourcen zu bezahlen, aber bevor ich das tue, möchte ich sicher sein, dass ich das richtige Sprachmodell ausgewählt habe.
Wenn Sie also auch neugierig sind, wie Sie ein Mixture-of-Experts- oder das große Qwen-110B-Chat-Modell und viele mehr mit nur einer Internetverbindung und ein paar Python-Zeilen betreiben können, dann schnallen Sie sich an! Sie sind hier richtig und ich werde Ihnen zeigen, wie Sie es auch tun können.
In diesem Artikel, Teil 1 einer Serie, werde ich Sie dabei anleiten, Python und Gradio_client zu verwenden, um einen KI-gestützten Chatbot mit einer textbasierten Schnittstelle zu erstellen. Die Terminal-Anwendung akzeptiert mehrzeilige Eingaben, was für Textanalysen, Zusammenfassungen und vieles mehr sehr nützlich ist…

textual app running Qwen1.5-MoE
In Teil 2 werde ich dasselbe Konzept anwenden, aber mit einer Streamlit Benutzeroberfläche. Der Chatbot wird auch ein schönes Streaming-Effekt haben (und es war wirklich schwer, ihn zu bekommen). Glauben Sie mir, Sie werden von den Ergebnissen begeistert sein!

Streamlit ChatBot with Qwen1.5–110B-chat
Hier sind die Schritte für dieses Projekt:
1.Vorbereitung der Umgebung und Paketabhängigkeiten
2.Erstellen der Gradio_client-Funktion zur Interaktion mit dem Hugging Face-Modell
3.Einrichtung der textuellen Schnittstelle, Farben und Streaming-EffekteLassen Sie uns ohne weitere Verzögerung beginnen.
1.Vorbereitung der Umgebung und Paketabhängigkeiten
Wir müssen nicht viele Bibliotheken installieren. Als gute Praxis erstellen wir eine virtuelle Umgebung, um dieses Projekt zu verwalten.
Erstellen Sie ein brandneues Verzeichnis (meines ist YourHFChat) und führen Sie den Befehl zur Erstellung der virtuellen Umgebung aus:
➜ mkdir HFChatAPI
➜ cd HFChatAPI
python3.10 -m venv venv #auf MAC/Linux - Ich verwende Python 3.10
python -m venv venv #auf WindowsUm die virtuelle Umgebung zu aktivieren:
source venv/bin/activate #für mac
venv\Scripts\activate #für Windows-BenutzerMit der aktivierten venv führen Sie die folgenden pip-Installationen für die erforderlichen Pakete aus:
pip install huggingface_hub #hugging face library für Python
pip install gradio-client==0.16.0 #geheimer API-Aufruf
pip install streamlit==1.24.0 #neueste Version von streamlit mit Chat-SchnittstelleWie Sie sehen können, installieren wir nicht pytorch oder tensorflow: Dies liegt daran, dass wir nur API-Inferenzen auf kostenlosen Hugging Face-Modellen durchführen, über die Use via API Gradio-Option.

Use via API Gradio-Option auf Hugging Face Space mit einem Demo-Chatbot
Dazu benötigen Sie ein Konto bei Hugging Face und müssen einen API-Token erstellen (Ihren persönlichen Autorisierungsschlüssel für API-Anfragen an die LLMs).
Auf der offiziellen Hugging Face-Seite für die API-Inferenz finden Sie die Anweisungen zum Abrufen des API-Tokens.
Aber was sind 🤗 Hosted Inference APIs? Eine API, kurz für Application Programming Interface, ist ein Satz von Regeln und Protokollen, die es verschiedenen Anwendungen ermöglichen, miteinander zu kommunizieren, auch wenn sie in verschiedenen Sprachen geschrieben sind.
Also erstellen wir ein Konto bei Hugging Face (falls Sie noch keines haben) und dann unseren ersten API-Token

Registrieren oder Anmelden unter https://huggingface.co/join
Nachdem Sie angemeldet sind, erstellen Sie einen Benutzerzugriff oder einen API-Token in Ihren Hugging Face-Profil-Einstellungen.
Sie sollten einen Token hf_xxxxx (alte Tokens sind api_XXXXXXXX oder api_org_XXXXXXX) sehen.

Beispiel aus meinem Hugging Face-Profil
Hinweis! Wenn Sie Ihren API-Token nicht übermitteln, wenn Sie Anfragen an die API senden, können Sie keine Inferenz auf Ihren privaten Modellen ausführen.
Erstellen Sie eine neue Python-Datei in Ihrem Hauptverzeichnis und nennen Sie sie Qwen110BChat.py
Jetzt, um zu überprüfen, dass alles funktioniert, importieren wir die Bibliotheken und führen sie aus:
# SPACE
https://huggingface.co/spaces/Qwen/Qwen1.5-110B-Chat-demo
import sys
from gradio_client import Client
Speichern Sie es und führen Sie dann aus Ihrem Terminal-Fenster, mit der aktivierten venv, den folgenden Befehl aus:
python Qwen110BChat.pyWenn Sie nichts erhalten… bedeutet das, dass es funktioniert 😁
Wir sind bereit.

Klicken Sie hier, um es kostenlos zu erhalten
2. Erstellung der Funktion zur Interaktion mit dem Hugging Face-Modell
Wie oben kurz erwähnt, werden wir nur die speziellen Gradio_client Inference-API-Aufrufe verwenden: Auf Hugging Face Hub, im SPACES Abschnitt, finden Sie eine Herde von öffentlichen, laufenden Gradio-Apps.


Viele von ihnen haben eine Option, die ganz unten auf der Seite geschrieben steht, um sie über die API zu verwenden. Dies ist für uns sehr praktisch: In der Regel hat ein Inference-API-Aufruf einen Preis, auch bei Hugging Face.
Da wir diese Funktion nur zum Testen verwenden, können wir uns mit den verfügbaren Spaces mit der Option „Use via API“ zufrieden geben 😉.
Werfen wir einen Blick auf unseren Qwen1.5–110B-Chat-Demo. Aus der Organisationskarte können wir sehen, dass dieses Modell das neueste Spitzenmodell der Qwen-Familie ist. Dieses Modell wiegt 250 GB… unmöglich für normale Menschen, es auszuführen!
Dies ist die Organisation von Qwen, die sich auf die großen Sprachmodelle (LLM) bezieht, die von Alibaba Cloud erstellt wurden. In dieser Organisation veröffentlichen wir kontinuierlich große Sprachmodelle (LLM), große Multimodal-Modelle (LMM) und andere AGI-bezogene Projekte. Jetzt haben wir Qwen veröffentlicht, eine große Sprachmodellfamilie, die von 0,5 Milliarden Parametern bis 110 Milliarden Parametern reicht. Außerdem haben wir Qwen-VL und Qwen-Audio veröffentlicht, die auf Qwen basierende Vision-Sprache- und Audio-Sprache-Modelle sind. Schauen Sie sie sich an und genießen Sie!
Ok, aber warum Qwen?
Das Qwen-Team strebt nach künstlicher allgemeiner Intelligenz und konzentriert sich derzeit auf den Aufbau von Generalist-Modellen, einschließlich großer Sprachmodelle und großer Multimodal-Modelle.
Dies bedeutet, dass das Team Open-Source unterstützt und kontinuierlich Modellserien veröffentlicht, einschließlich der Sprachmodelle, wie Qwen-7B , Qwen-14B und Qwen-72B, sowie deren Chat-Modelle und Multimodal-Modelle, wie Qwen-VL und Qwen-Audio.

Sie können es im Grunde mit allem verwenden!
In letzter Zeit haben wir einen Ausbruch von großformatigen Modellen mit über 100 Milliarden Parametern in der Open-Source-Community gesehen. Diese Modelle haben eine beeindruckende Leistung in sowohl Benchmark-Tests als auch im Chatbot-Bereich gezeigt.
Heute veröffentlichen wir das erste 100B+-Modell der Qwen1.5-Serie, Qwen1.5–110B, das eine vergleichbare Leistung mit Meta-Llama3–70B … am 25. April 2024 veröffentlicht von Quelle
Das Qwen-Team hat mit Frameworks wie vLLM, SGLang für die Bereitstellung, AutoAWQ, AutoGPTQ für die Quantisierung, Axolotl, LLaMA-Factory für das Feintuning und llama.cpp für die lokale LLM-Inferenz zusammengearbeitet, die alle jetzt Qwen1.5 unterstützen. Die Qwen1.5-Serie ist auf Plattformen wie Ollama und LMStudio verfügbar. Darüber hinaus werden API-Dienste nicht nur auf DashScope, sondern auch auf together.ai angeboten, mit weltweiter Verfügbarkeit. Besuchen Sie hier, um loszulegen, und wir empfehlen, Qwen1.5–72B-chat auszuprobieren.
Ein weiterer erstaunlicher Grund, sich für die Qwen-Modelle zu entscheiden, hängt mit der Lizenz und den unterstützten Sprachen zusammen.
Lizenzvereinbarung
Überprüfen Sie die Lizenz für jedes Modell innerhalb seines HF-Repositorys. Es ist nicht erforderlich, dass Sie eine Anfrage für die kommerzielle Nutzung stellen.
Unterstützte Sprachen
Die Basismodelle von Qwen1.5 zeigen beeindruckende multilinguale Fähigkeiten, wie in verschiedenen Bewertungen mit 12 Sprachen (ar, es, fr, pt, de, it, ru, ja, ko, vi, th, id) gezeigt. In Bewertungen, die verschiedene Dimensionen wie Prüfungen, Verständnis, Übersetzung und Mathematik abdecken, liefert Qwen1.5 konsequent starke Ergebnisse. Von Sprachen wie Arabisch, Spanisch und Französisch bis hin zu Japanisch, Koreanisch und Thai demonstriert Qwen1.5 seine Fähigkeit, hochwertige Inhalte in verschiedenen sprachlichen Kontexten zu verstehen und zu generieren. Wir haben Qwen1.5–72B-Chat mit GPT-3.5 verglichen, und die Ergebnisse sind unten dargestellt:

Bild von https://qwenlm.github.io/blog/qwen1.5/
Diese Ergebnisse zeigen die starken multilingualen Fähigkeiten der Qwen1.5-Chat-Modelle, die für Downstream-Anwendungen wie Übersetzung, Sprachverständnis und Multilingual-Chat eingesetzt werden können. Wir glauben auch, dass die Verbesserungen in den multilingualen Fähigkeiten die allgemeinen Fähigkeiten verbessern können.
Zurück zur Funktion…
Ok, da Qwen gut ist, erstellen wir eine Funktion, um die Kommunikation mit dem Gradio_client über die API herzustellen.
Die Details können auf jeder Hugging Face Space-Chat-Demo abgerufen werden. Zum Beispiel:

Schauen Sie sich die Details an:
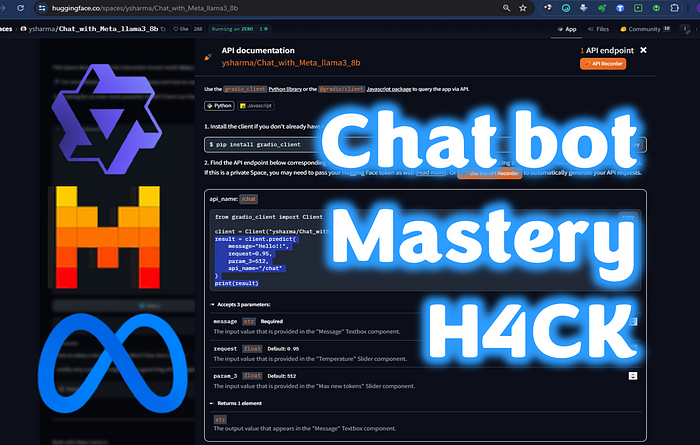
from gradio_client import Client
client = Client("ysharma/Chat_with_Meta_llama3_8b")
result = client.predict(
message="Hello!!",
request=0.95,
param_3=512,
api_name="/chat"
)
print(result)Wir haben auch alle relevanten Erklärungen (manchmal etwas schwer zu verstehen…)
Akzeptiert 3 Parameter:
message: str Required - Der Eingabewert, der im Textfeld "Message" bereitgestellt wird.
request: float Default: 0.95 - Der Eingabewert, der im Schieberegler "Temperature" bereitgestellt wird.
param_3: float Default: 512 - Der Eingabewert, der im Schieberegler "Max new tokens" bereitgestellt wird.Gibt 1 Element zurück:
str: Der Ausgabewert, der im Textfeld "Message" angezeigt wird.
Die Details der API-Parameter (Eingaben und Ausgabe), aber Sie können auch diese Methode verwenden
Unsere Funktion muss also zuerst den Client aufrufen und die Verbindung herstellen:
# SPACE
https://huggingface.co/spaces/Qwen/Qwen1.5-110B-Chat-demo
import time import sys from gradio_client import Client
Set HF API token and HF repo
yourHFtoken = "hf_xxxxxxxxxxxxxxxxxxxxxx" #hier Ihr HF-Token
repo = 'Qwen/Qwen1.5-110B-Chat-demo'
def ConncetLLM(reponame,hftoken):
print('Laden der API-Gradio-Client für Qwen1.5-110B-Chat-demo')
client = Client(reponame, hf_token=hftoken)
return client
#instantiate the Gradio_client object
client = ConncetLLM(repo,yourHFtoken)
Mit der letzten Zeile wird die API-Kommunikation gestartet. Jetzt sind wir bereit, unsere Anweisungen zu senden und die Modellantworten zu erhalten.
Es gibt mehr als eine Methode…
Die Vorlage aus dem Hugging Face-Space von den Bildern zeigt den API-Aufruf wie folgt:
result = client.predict(
message="Hello!!",
request=0.95,
param_3=512,
api_name="/chat"
)Die predict-Methode ist gut, aber sie wird Ihnen nur die endgültige Antwort geben, ohne Streaming. Dies bedeutet, dass wir hier zwei Optionen haben:
- Verwenden Sie die
predict()und warten Sie, bis die gesamte Antwort von der API zurückgegeben wird - Verwenden Sie die
submit()-Methode und nutzen Sie den Streaming-Effekt.
Die verfügbaren Optionen sind in der offiziellen Dokumentationsseite für den Gradio_client gut beschrieben.
3. Einrichtung der textuellen Schnittstelle, Farben und Streaming-Effekte
Die textuelle Schnittstelle ist recht einfach, aber ich habe versucht, sie mit einigen Farben, einem Schreib-Effekt und der Möglichkeit, mehrere Zeilen in der Eingabe zu haben, zu verschönern.
Für die Farben werden wir die ANSI-Escape-Sequenz verwenden

Bild von https://stackoverflow.com/questions/4842424/list-of-ansi-color-escape-sequences
Alle Details in diesem erstaunlichen Beitrag von stackoverflow.

meine Farben
Das gesagt, wir werden eine while-Schleife starten, die nur beendet wird, wenn unsere Eingabe „quit!“ lautet (if "quit!" in lines[0].lower():)
HINWEIS: Machen Sie sich keine Sorgen über den Code, Sie finden alles in meinem GitHub-Repository.
while True:
userinput = ""
print("\033[1;30m") #dunkelgrau
print("Geben Sie Ihren Text ein (beenden Sie die Eingabe mit Ctrl+D auf Unix oder Ctrl+Z auf Windows) - geben Sie quit! ein, um den Chatroom zu verlassen:")
print("\033[38;5;48m") #User-Eingabe-Farbe
lines = sys.stdin.readlines()
for line in lines:
userinput += line + "\n"
if "quit!" in lines[0].lower():
print("\033[0mBYE BYE!")
break
print("\033[1;30m") #dunkelgrau
print('Aufruf der Gradio_client-Vorhersage...')
result = client.submit(
query=userinput,
history=[],
system="Du bist ein hilfreicher Assistent.",
api_name="/model_chat"
)
print("\033[38;5;99m")
final = ''
for chunk in result:
if final == '':
final=chunk[1][0][1]
print(chunk[1][0][1], end="", flush=True)
else:
try:
print(chunk[1][0][1].replace(final,''), end="", flush=True)
final = chunk[1][0][1]
except:
pass - In der
resultVariablen speichern wir das Ergebnis des .submit()-Methodenaufrufs: es ist ein iterierbares Objekt, das gut für das Streaming unserer Ausgabe ist… aber es hat mich eine Weile gekostet, um den Trick zu finden, um es reibungslos laufen zu lassen - Die
for-Schleife mag Ihnen etwas seltsam vorkommen: Der Grund dafür ist, dass Qwen Gradio API nicht eine Zeichenkette, sondern ein Tupel aus 3 Elementen zurückgibt… und unsere Zeichenkette Antwort ist im zweiten Element, das eine Liste ist. Schauen Sie hier:

Zugriff auf die Zeichenkette über result[1][0][1]
Wenn wir die for-Schleife starten, werden wir die endgültige Ergebnis-Token für Token durchlaufen. Ich habe es gedruckt und zu meiner Überraschung ist es eine inkrementelle Zeichenkette
Wissenschaft
Wissenschaft ist
Wissenschaft ist ein
Wissenschaft ist ein systematisches
Wissenschaft ist ein systematisches und
Wissenschaft ist ein systematisches und logisches
...Also ist das erste, was wir tun müssen, dass in dem Fall, dass wir uns in der ersten Iteration befinden, haben wir keine Probleme: die empfangene Textzeile ist gleich der endgültigen Zeichenkette
if final == '':
final=chunk[1][0][1]
print(chunk[1][0][1], end="", flush=True)
else:
try:
print(chunk[1][0][1].replace(final,''), end="", flush=True)
final = chunk[1][0][1]
except:
passIn den folgenden Iterationen nehmen wir den Chunk und subtrahieren davon, was bereits generiert wurde (endgültig). Auf diese Weise werden nur die neuen Zeichen in der Konsole gedruckt.
Und los geht’s. Speichern Sie die Datei und führen Sie im Terminal, mit der noch aktivierten venv, den folgenden Befehl aus:
python Qwen110BChat.pyDenken Sie daran, dass wir mehrzeilige Eingaben erwarten, wir müssen also signalisieren, wann es Zeit ist, sie zu beenden: Wir beenden die Eingabe mit Ctrl+D auf Unix oder Ctrl+Z auf Windows

Die Ergebnisse Ihrer Bemühungen

Und denken Sie daran…
Zwischenfazit… für jetzt
In diesem ersten Teil haben wir gelernt, wie wir die geheime Gradio-API-Anrufe nutzen können, um sehr große LLMs auf unserem Computer zu verwenden. Ich habe bisher (mit Blick auf die Hugging Face Spaces…) die folgenden getestet:
Blossom-14B
llama3chat-8B
mistralSFast-7B
openELM3BChat-3B
phi3mini128Chat-4B
Qwen110BChat
QwenMoEChat-2x7BIn Teil 2 werden wir sehen, wie wir unserem KI-Assistenten mit Streamlit eine schöne GUI geben können.
Hier ist das GitHub-Repository für diesen Artikel: