Nach mehr als 6 Jahren Arbeit im Bereich des maschinellen Lernens, dem Start von drei KI/LLM-Startups und dem Aufbau zahlreicher Projekte und Pipelines habe ich mit vielen LLM-Tools experimentiert – von RAG- und Agent-Frameworks bis hin zu LLM-basierten Diensten mit ordnungsgemäßen Tests, CI/CD und Beobachtbarkeit.
Dieser Artikel ist eine Liste der Tools, die mir aus verschiedenen Gründen am besten gefallen haben. Wir werden den gesamten Entwicklungszyklus einer LLM-Anwendung durchlaufen – von RAG-Datenbanken und Agenten bis hin zu API-Endpunkten mit HTTPS und automatisierten Bereitstellungspipelines mit ordnungsgemäßer Beobachtbarkeit, während wir die Frameworks und Tools für jeden Schritt überprüfen.
Noch eine Sache – Sie müssen nicht mit dem Technologie-Stack einverstanden sein, den ich auswähle; jedoch wähle ich meine Tools hauptsächlich nach Benutzerfreundlichkeit aus. Beispielsweise können Sie einen großen Cloud-Anbieter wie Azure verwenden, anstatt Dinge auf einem VPS zu bereitstellen – und Sie erhalten eine bessere Skalierbarkeit, mehr Out-of-the-Box-Dienste und so weiter. Aber es wird viel mehr Zeit in Anspruch nehmen, alles zu beherrschen, und Sie werden anfälliger für eine Anbieterbindung. Wenn Sie einen VPS mit Coolify verwenden (über den wir später sprechen werden), dauert es etwa 10 Minuten, um loszulegen, und Sie erhalten alles, was Sie benötigen – Datenbanken, Frontend-/Backend-Bereitstellungen, automatisiertes CI/CD und Backups – mit einer intuitiven und benutzerfreundlichen Benutzeroberfläche.

Foto von Ahmad Dirini auf Unsplash
LLM-API und Selbstgehostete Optionen
Es gibt zwei Hauptoptionen für große Sprachmodell-APIs:
- Wenn Sie eine selbstgehostete Version bevorzugen, ist Ollama die beste Wahl. Sie fragen sich vielleicht: „Warum sollte man ein selbstgehostetes LLM benötigen? Es ist teurer, schwieriger einzurichten und die Antwortqualität ist niedriger“. Die Antwort ist einfach – Privatsphäre. Ich habe bereits über Privatsphäre und LLMs geschrieben, aber kurz gesagt – wenn Sie eine API verwenden, teilen Sie Ihre Daten mit anderen Unternehmen, und diese Unternehmen teilen Ihre Daten mit noch mehr Drittparteien. Bei einigen Projekten ist dies ein No-Go.
- Wenn das Projekt keine hohe Privatsphäre und Sicherheit erfordert, verwende ich immer Openrouter. Es ist besser als jeder andere LLM-Anbieter, einfach weil es auf mehreren Anbietern basiert und Ihnen eine einfache Schnittstelle bietet, um mit jedem von ihnen zu interagieren. Wenn Sie Ihre Pipeline für ein LLM geschrieben haben, können Sie das LLM einfach durch Ändern weniger Zeichenfolgen in den Anfragen wechseln. Keine zusätzlichen Bibliotheken, kein Anbieterwechsel, es ist einfach so einfach. Wenn Sie mehr wissen möchten, lesen Sie meinen Openrouter-Leitfaden.
Es gibt viele andere LLM-Anbieter wie together.ai, Mistral und so weiter; dennoch mag ich Openrouter mehr wegen der einfachen Benutzeroberfläche und der zusätzlichen nützlichen Funktionen, die es bietet (automatisches Logging, Modellvergleich, automatisierte Modellauswahl, kostenlose Testversion und so weiter).

Ollama und OpenRouter
RAG-Datenbanken
Die meisten LLMs haben Probleme wie:
- Keine aktuellen Informationen;
- Keine Fachkenntnisse;
- Halluzinationen;
- Keine Zitierung von Quellen;
- Voreingenommene Antworten.
All diese Probleme können mit einem ordnungsgemäßen RAG (Retrieval Augmented Generation) behoben werden. Alle RAG-Algorithmen erfordern in irgendeiner Form eine Vektordatenbank. Dies sind meine bevorzugten Optionen:
- ChromaDB – perfekt für die Prototypenentwicklung und PoC (Proof of Concept). Es ist extrem einfach einzurichten (da es auf SQLite basiert, sodass Ihre DB nur eine Datei auf Ihrem PC ist) und die Nutzung ist sehr intuitiv und gut dokumentiert.
- Für ernsthaftere Projekte verwende ich Supabase (das auf PostgreSQL basiert) mit dem PGVector-Plugin. Einige Vorteile von Supabase sind die intuitive und benutzerfreundliche Benutzeroberfläche, viele Funktionen wie Backups, Rollenmanagement, APIs und ein Python-Paket. Es gibt auch viele Anleitungen zur Nutzung von Supabase, und was mir persönlich gefällt, ist, dass es Open-Source ist und Sie es auf Ihrem eigenen Server selbst hosten können.
Normalerweise verwende ich maßgeschneiderte Lösungen, aber manchmal kann LangChain bei der Erstellung von RAG-Pipelines sehr hilfreich sein.

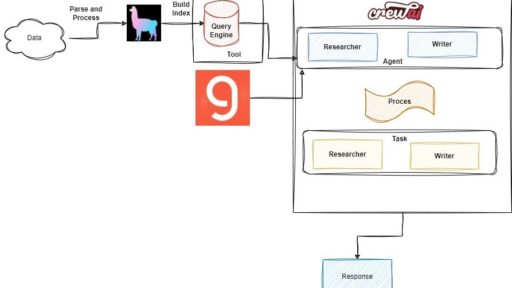
Agenten
Wenn Sie eine komplexere LLM-Pipeline erstellen oder schwierige Probleme mit LLMs lösen möchten, müssen Sie einen agentenbasierten Ansatz verwenden. Ein LLM-Agent ist ein KI-System, das sequenzielles (schrittweises) Denken verwendet. Im Grunde genommen geben Sie ihm anstelle eines Satzes von Anweisungen vollständige Freiheit und ein Set von Tools, um das Problem zu lösen.
Hier sind die Python-Bibliotheken, die ich zur Erstellung von Agenten verwende:
- LangChain – das derzeit beliebteste Framework für Agenten, es hat eine großartige Dokumentation, eine große Community und viele Tutorials mit Anleitungen. Eine Empfehlung von mir ist, die Methode initialize_agent anstelle der neuen Methoden wie create_react_agent oder create_json_agent zu verwenden. Der Hauptgrund dafür ist, dass die neuen Methoden noch nicht so viele Anleitungen und Anweisungen haben und für mich persönlich etwas verwirrend waren. Die
initialize_agent-Methode ist einfacher zu verwenden und hat Dutzende von Anleitungen mit verschiedenen Ansätzen. - LlamaIndex – der Hauptkonkurrent von LangChain, bekannt für seine großartige Optimierung in Bezug auf Indexierung und Datenabruf. Kurz gesagt, wenn Sie eine RAG-Pipeline aufbauen, kann LlamaIndex die schnellere und bessere Option sein; für komplexere Projekte und Pipelines ist es jedoch besser, LangChain zu verwenden.
Im Allgemeinen ist es besser, mit dem Lernen von LLMs mit LangChain zu beginnen, da es funktionsreicher und einfacher zu verwenden ist.
Beobachtbarkeit
Wenn Sie Ihre LLM-Anwendung bereitgestellt haben, müssen Sie die Antwortqualität, Genauigkeit und Geschwindigkeit messen. Aber wie kann man das bei LLMs tun? Es gibt zwei Lösungen, die ich verwende, beide sind Open-Source-LLM-Beobachtungsplattformen, die Tracing, Bewertung, Visualisierung und Überwachung bieten:
- Arize Phoenix
- LangSmith
Ich fand LangSmith etwas einfacher zu verwenden; sie haben eine sehr schöne Möglichkeit, Eingaben-Ausgaben zu verfolgen, und Bewertungen sind ziemlich schnell zu entwickeln. Phoenix hingegen hat eine bessere kostenlose Stufe, da sie mehr Datenverfolgung ermöglichen. Wenn Sie mit der LLM-Beobachtbarkeit beginnen möchten, kann ich LangSmith sicher empfehlen – es ist perfekt für PoC und Prototyping.

Arize vs Phoenix
Backend
Für das Backend verwende ich immer Python, FastAPI und Pydantic. Hier ist eine kurze Liste der Gründe dafür:
- FastAPI ist ziemlich schnell, hat eine sehr gute Dokumentation und enthält alle Funktionen, die Sie für die Entwicklung von LLM-Anwendungen benötigen, wie Datenbank-ORMs, Authentifizierung, CORS und Multi-Threading-Bereitstellungen.
- Pydantic hilft Ihnen, Ihren Funktionen und Endpunkten eine strenge Typisierung hinzuzufügen, sodass Sie immer sicher sein können, dass alle Variablen den gewünschten Typ haben; es hilft, Ihre Anwendung fehlerfrei zu machen.
Normalerweise kombiniere ich sie mit Gunicorn + Uvicorn-Workern, damit ich mehrere Anfragen gleichzeitig bearbeiten kann.
Dennoch können Sie jedes Backend-Framework (Flask, Django) verwenden, da alle gängige Funktionalitäten bieten und alle produktionsbereit sind.
Bereitstellung
Für Bereitstellungen containerisiere ich meine Anwendungen immer mit Docker. Die Hauptgründe dafür sind:
- Reproduzierbarkeit – wenn Sie ein Docker-Image mit Ihrer App erstellen, können Sie es auf jedem System und jeder CPU-Architektur ausführen;
- Skalierbarkeit – wenn Ihre App dockerisiert ist, ist es einfach, mehrere Instanzen zu starten oder sie auf einem Cluster bereitzustellen;
- Bereitstellung – es ist sehr einfach, Docker-Images bereitzustellen, insbesondere mit Docker Compose. Sie können eine Datenbank, einen Reverse-Proxy und ein Backend zu Ihrer
docker-compose.yml-Datei hinzufügen und alles auf einmal bereitstellen, ohne sich um alles separat kümmern zu müssen.
Um meine Docker-Images bereitzustellen, verwende ich Coolify – es ist eine Open-Source, selbstgehostete Plattform, die den Bereitstellungsprozess erheblich vereinfacht und Folgendes bietet:
- Automatisierte SSL-Zertifikatsverwaltung – Sie müssen sich keine Sorgen machen, dass Ihr Backend https-kompatibel ist;
- Keine Anbieterbindung – Sie können Coolify auf jedem VPS oder Cloud-Anbieter bereitstellen und eine Abstraktionsebene hinzufügen, die Ihnen Freiheit von allen Anbietern bietet;
- Einfacher Reverse-Proxy – Sie müssen sich nicht um Sicherheit und Domains kümmern, da Sie in Coolify nur die gewünschte Domain angeben müssen;
- Automatisierte Datenbank-Backups – wenn Sie gängige Images wie PostgreSQL, MySQL, Redis und viele andere verwenden, können Sie Backups einfach per Klick einrichten, anstatt benutzerdefinierte Lösungen zu schreiben oder Geld zu bezahlen;
- CI/CD-Pipeline – durch die Verbindung mit Ihrem GitHub erhalten Sie automatisch eine kostenlose automatische Bereitstellungspipeline. Wann immer Sie Updates an Ihrer App vornehmen, wird sie automatisch bereitgestellt;
- Kollaborative Funktionen – Sie können Coolify mit Ihrem Team teilen und gemeinsam an verschiedenen Aspekten Ihrer App arbeiten, ohne sich gegenseitig zu stören. Sie können auch Berechtigungen für jeden Benutzer steuern;
- Überwachung und Benachrichtigungen – Sie können eine von vielen Apps wie Telegram/Discord verwenden und Benachrichtigungen erhalten, wenn etwas mit Ihren Bereitstellungen passiert.

Coolify – einfach, funktionsreich und hübsch
Zusammenfassung
In diesem Artikel haben wir einen schönen Technologie-Stack für die Erstellung Ihrer eigenen LLM-Anwendungen behandelt. Durch die Verwendung dieser Tools erhalten Sie:
- Eine zuverlässige, benutzerfreundliche Vektor-Datenbank;
- LLMs für jedes Problem, in verschiedenen Größen und mit ordnungsgemäßer Privatsphäre;
- Keine Anbieterbindungen;
- Ordnungsgemäßes Logging und Monitoring für Ihre Pipelines;
- Eine skalierbare und wartbare Möglichkeit, Ihre Anwendungen einfach bereitzustellen.