

Im Artikel Verbessern Prompt-Strukturen die Ausgabequalität? habe ich eine Analyse der von GPT-4, Gemini 1.5 und Claude 3 generierten Antworten zu verschiedenen Zero-Shot-Prompts für eine komplexe Aufgabe durchgeführt – die Bewertung von Besprechungsprotokollen nach Kriterien. Diese Prompts erforderten detaillierte Anweisungen für ein Modell (LLM), sodass die Prompt-Größe bis zu 400 Wörter betrug.
Nun wollen wir herausfinden, was effektiver ist: ausführliche Anweisungen zu schreiben oder der künstlichen Intelligenz Beispiele für die gewünschte Ausgabe zu geben. Diese Strategie wird als Few-Shot-Prompting bezeichnet.
Dieser Artikel präsentiert einen experimentellen Vergleich dieser beiden alternativen Prompting-Strategien, die auf dieselbe Aufgabe mit denselben drei LLMs angewendet wurden, und auch GPT-4o wird getestet.
Ich möchte dieselbe Frage beantworten: Wie können wir unseren Aufwand beim Erstellen von Prompts minimieren, ohne die Ausgabequalität zu beeinträchtigen?
1. Few-Shot-Prompting und ausführliche Beispiele
Es ist erwähnenswert, dass „Few-Shot“ nicht der einzige Begriff für diesen Ansatz ist. Zum Beispiel wird es auch als Beispiel-Demonstrationen in der Liste der „Prompt-Design-Prinzipien“ aus diesem Artikel (Dezember 2023) bezeichnet:
„One-Shot-Prompts“ werden manchmal als anders als „Few-Shot-Prompts“ betrachtet. Dennoch verwende ich denselben Begriff „Few-Shot“ für ein Prompt mit nur einem Beispiel.
Few-Shot-Prompting wird angenommen, dass es die Qualität verbessert. Das heißt, KI kann viele Nuancen aus den Beispielen dessen, was wir erwarten, extrahieren. Meine Experimente zeigen, dass dies tatsächlich der Fall ist.
In den meisten Quellen werden Few-Shot-Beispiele für KI-Aufgaben mit sehr kurzen Ausgaben beschrieben, die von wenigen Wörtern bis zu einigen Dutzend Wörtern reichen.
Das Ergebnis der Analyse eines Protokolls muss jedoch erheblich länger sein, typischerweise Hunderte von Wörtern, nicht Dutzende. Ich habe keine Hinweise im Internet gefunden, die nahelegen, dass der Aufwand für die Erstellung solcher langer Beispiele durch die Qualität des Ergebnisses gerechtfertigt ist. Deshalb habe ich beschlossen, dies selbst zu erkunden.
Wenn Sie bereits ein vollständiges Beispiel dafür haben, was die KI mit Ihrer Aufgabe machen soll, wird das Hinzufügen zu einem Prompt definitiv Zeit beim Schreiben des Prompts sparen.
Dies liegt daran, dass Beispiele oft die Notwendigkeit detaillierter Aufgabenbeschreibungen im Prompt beseitigen und die Notwendigkeit verringern, andere Prompt-Engineering-Techniken anzuwenden.
Eine Technik sollte jedoch immer noch in Kombination mit langen Few-Shot-Beispielen verwendet werden, um sicherzustellen, dass das LLM klar „versteht“, wo das Beispiel beginnt und endet. Es gibt mehrere Techniken dafür (siehe Abschnitt 3.2); ich verwende typischerweise .
2. Wie erhält man Beispiele?
Wenn Ihr Ziel darin besteht, lange Texte zusammenzufassen oder Social-Media-Beiträge zu erstellen, haben Sie wahrscheinlich bereits Beispiele für effektive Zusammenfassungen oder ansprechende Beiträge. Diese Beispiele können direkt in das Prompt eingefügt werden, ohne dass Änderungen erforderlich sind.
Nicht alle Situationen sind jedoch so einfach. Zum Beispiel hatte ich keine bestehenden Beispiele für die Besprechungsanalyse, da es sich um eine neuartige Aufgabe handelte, die von Menschen noch nicht angegangen wurde; sie ist einfach zu arbeitsintensiv.
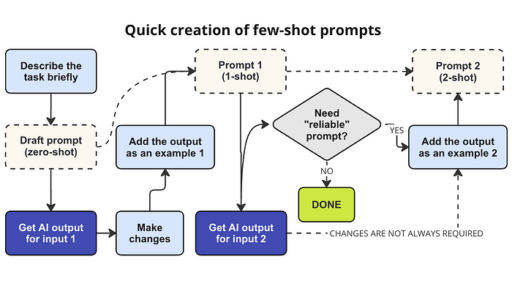
Wie können Sie ein hochwertiges Beispiel mit minimalem Aufwand erstellen?
Hierbei ist generative KI auch hilfreich:
- Beginnen Sie mit dem Schreiben eines grundlegenden (Entwurf-)Prompts, das die Aufgabe anspricht. Dies ist das Prompt, dem später Beispiele hinzugefügt werden.
- Wenden Sie dieses grundlegende Prompt zunächst wie es ist auf einige Eingabedaten an, um eine vorläufige Ausgabe zu erhalten.
- Diese vorläufige Ausgabe dient dann als Beispiel, muss jedoch manuell verfeinert und ihre Fehler korrigiert werden. Experimente zeigen (siehe Abschnitt 3.3), dass die Einbindung nur eines solchen Beispiels die Qualität des Prompts erheblich verbessern kann.
- Ein zweiter Durchgang kann bei Bedarf durchgeführt werden:
- 4a. Wenden Sie das in Schritt 3 entwickelte 1-Shot-Prompt auf andere Eingabedaten an als in Schritt 2.
- 4b. Durch die Einbeziehung des KI-generierten Textes (4a) als zweites Beispiel erstellen Sie ein 2-Shot-Prompt.
- 4c. Dies erhöht die „Zuverlässigkeit“ des Prompts und verbessert dessen Fähigkeit, konsistent qualitativ hochwertige Ausgaben bei unterschiedlichen Eingabedaten zu erzeugen.

In Abschnitt 3.3 können Sie mehr darüber erfahren, wie ich diesen Ansatz in meinem Projekt angewendet habe.
3. Prompts zum Studieren
3.1. Zero-Shot-Prompts
Prompt #1 ist ein „minimales“ Prompt, das Besprechungsprotokolle basierend auf festgelegten Kriterien analysieren und Verbesserungen für zukünftige Besprechungen vorschlagen kann.
Prompt #2 entwickelte sich aus Prompt #1 durch zahlreiche Verfeinerungen und ist daher doppelt so groß. Es enthält detaillierte Anweisungen, Überschriften und Listen, ohne jedoch explizite Schritte für die KI festzulegen. Dieses Prompt wurde als das beste unter den getesteten Zero-Shot-Prompts im Abschnitt 3 des vorherigen Artikels gefunden:
Bemerkenswerte Verbesserungen von Prompt #2 gegenüber Prompt #1 wurden jedoch nur bei Claude 3 Opus beobachtet.
3.2. Hinzufügen eines Beispiels
Hier ist ein Beispiel für eine Protokollanalyse-Ausgabe, die in das Zero-Shot-Prompt #1 integriert wurde und das 1-Shot Prompt #3 erstellt hat.

Beispiel in Prompt #3
Wie wir sehen können, können Beispiele ziemlich lang sein und sogar das gewünschte Format enthalten: in diesem Fall die Verwendung von **, um fettgedruckten Text zu kennzeichnen, und Zahlen, um eine Liste zu strukturieren.
Hier habe ich eine Struktur mit Eröffnungs- und Schluss-Tags (…) verwendet, um den Anfang und das Ende des Beispiels zu kennzeichnen. Diese Struktur wird von LLMs verstanden. Tags werden von Anthropic empfohlen; ihr Prompt-Generator organisiert Prompts für Claude mit Tags.
Wenn Sie jedoch einen solchen „programmierten“ Ansatz wie Tags nicht bevorzugen, gibt es alternative Methoden, das Beispiel von anderem Text zu trennen:
- Wenn Ihr Prompt Markdown-ähnliche Überschriften verwendet, lassen Sie das Beispiel auch unter der Überschrift „# Beispiel“ stehen.
- Wenn es keine anderen Überschriften in Ihrem Prompt gibt, können Sie beliebige Trennzeichen wie dieses verwenden:
Beispiel:
„`
…(Beispieltext)…
„`
3.3. Erstellen von Beispielen mit KI
Das oben besprochene Beispiel ist eine Ausgabe des Zero-Sh
ot-Prompt #1, das mit dem GPT-4-Modell generiert wurde. Ich habe die Ausgabe jedoch manuell angepasst, indem ich zu großzügige Bewertungen reduziert und das Bewertungsformat an meine Vorlieben angepasst habe.
Anschließend habe ich das 1-Shot-Prompt #3 zur Analyse einer anderen Besprechung verwendet. Dieses Mal habe ich das Gemini 1.5 Pro-Modell verwendet, um sicherzustellen, dass das neue Ergebnis einen anderen Stil hatte. Diese neue Ausgabe wurde das zweite Beispiel im neuen 2-Shot Prompt #4. Ich folgte also der Formel: Prompt #4 = Prompt #3 + zweites Beispiel.
Empfohlene Schritte zum Erstellen eines 1-Shot-Prompts und eines 2-Shot-Prompts
Um Beispiele in Prompt #4 zu trennen, habe ich wieder Tags verwendet, die wie folgt angeordnet sind:
……

Beispiel 2 in Prompt #4
Beachten Sie, dass es eine Begrenzung der Größe des System-Prompts in GPT („Anweisungen“) gibt – 8000 Zeichen einschließlich Leerzeichen. Daher habe ich einige Elemente aus der Liste in jedem Beispiel in Prompt #4 entfernt.
Als Ergebnis sind die Beispiele im 2-Shot-Prompt so unterschiedlich wie möglich. Dies sollte die Ausgaben bei neuen Eingabedaten im Vergleich zu denen des 1-Shot-Prompts verbessern. Diese Behauptung bleibt jedoch ungetestet, da solche Tests eine große Anzahl verschiedener Protokolle (viele verschiedene Eingabedatensätze) erfordern würden.
Lassen Sie uns eine einfachere Behauptung testen – dass Few-Shot-Prompts Zero-Shot-Prompts übertreffen.
4. Prompt-Vergleichsergebnisse
Daher vergleichen die Experimente vier Prompts:
- 0-Shot: eine kurze Aufgabenbeschreibung.
- 0-Shot: detaillierte Anweisungen.
- 1-Shot: kurzes Prompt (wie in Punkt 1) erweitert um ein Beispiel.
- 2-Shot: kurzes Prompt (wie in Punkt 1) erweitert um zwei Beispiele.
Die Details zu den Experimenten sind im Abschnitt 2 des Artikels „Verbessern Prompt-Strukturen die Ausgabequalität?“ verfügbar. Insbesondere beschreibt er die Methode, die verwendet wurde, um die Ausgabequalität anhand der „Anzahl der Defekte“ zu bewerten.
Diesmal gibt es 2 Änderungen in der beschriebenen Methodik:
- Das brandneue GPT-4o-Modell wird zusätzlich zu GPT-4-turbo getestet. GPT-4o wird auf dem Open AI Playground verwendet.
- Defekte von Anfangsnachrichten (die nicht mit der endgültigen Analyse zusammenhängen) werden NICHT berücksichtigt; diese Defekte sind für die Zwecke dieser Studie irrelevant.
Hier sind die Ergebnisse, gemessen an der oben genannten Metrik:

Ergebnisszusammenfassung für verschiedene Prompts. Je höher die Zahl, desto schlechter die Ausgabequalität.
Im Durchschnitt produzieren Few-Shot-Prompts deutlich bessere Texte.
Hier ist, was wir im obigen Diagramm in Bezug auf Modellunterschiede beobachten:
- GPT-4o, GPT-4 und Gemini excel at extracting user expectations from examples (wobei Gemini sogar spezifische Phrasen repliziert, was normalerweise eine praktische Funktion ist). Ein zu detailliertes Prompt ohne Beispiele kann jedoch zu Verwirrung bei allen diesen Modellen führen, unabhängig vom strukturierten Format des Prompts.
- Im Gegensatz dazu zeigt Claude 3 Opus eine Vorliebe für detaillierte Anweisungen gegenüber Beispielen und folgt Anweisungen rigoros. Alle drei Prompts mit kurzen Anweisungen führten zu Problemen in Claudes Ausgaben.
Für eine detaillierte Liste der Defekte in jedem Experiment können Sie die Tabelle einsehen.
Das obige Diagramm hat nichts mit einem anderen wichtigen Indikator zu tun – „Textspezifität„. Leider ist dieser Indikator schwer zu quantifizieren, aber meine persönliche Beobachtung ist, dass die Verwendung von Beispielen die Modellausgaben in Bezug auf die Spezifität nahezu ideal gemacht hat.
Bemerkenswerterweise begann GPT-4, das zu vagen Antworten auf Zero-Shot-Prompts neigt, mehr auf spezifische Details aus dem Protokoll zu achten, wenn Beispiele bereitgestellt wurden.
Wie erwartet funktioniert GPT-4o extrem gut, insbesondere bei Few-Shot-Prompts. Bei der Analyse von 6 Protokollen mit meinen Prompts #3 und #4:
- Es gab überhaupt keine „Defekte“.
- Die Ausgaben waren perfekt spezifisch und verwendeten viele Details aus den Beispielen.
Vor dem 13. Mai 2024 schnitt Gemini 1.5 Pro besser ab als alle anderen Modelle in Bezug auf „Textspezifität“. Jetzt ist GPT-4o der Führer nach diesem subjektiven Kriterium, selbst wenn keine Beispiele bereitgestellt werden. Werfen Sie einfach einen Blick auf seine Analyse einer Besprechung:


GPT-4o-Analyse einer täglichen Besprechung, Prompt #2
Few-Shot-Prompting hat jedoch in einigen Fällen seine Nachteile. Ich habe festgestellt, dass Claude bei der Verwendung von 1–2-Shot-Prompts dazu neigt, Fehler zu machen, die auf eine Übersehen von Anweisungsdetails zurückzuführen sind. Dies liegt wahrscheinlich an der sehr großen Größe meiner Few-Shot-Prompts, die den Fokus dieses Modells von der Hauptaufgabe ablenken können.
Es ist wichtig, die probabilistische (zufällige) Natur von KI-Ausgaben anzuerkennen. Interessanterweise wird die Zufälligkeit mit Few-Shot-Prompts erheblich reduziert im Vergleich zu Zero-Shot-Prompts. Insbesondere war die „Anzahl der Defekte“-Metrik bei wiederholten Läufen desselben Modells mit demselben Kontext konsistent ähnlich.
Diese und andere Vorteile von Few-Shot-Prompting finden Sie hier:
5. Fazit
Few-Shot-Prompting ist eine großartige Methode, um Prompts mit minimalem Aufwand zu erstellen und gleichzeitig eine hohe Qualität zu erzielen. Es führt zu spezifischeren und weniger fehlerhaften Texten, obwohl die getesteten Few-Shot-Prompts sehr groß sind (theoretisch könnten sie ein Modell „verwirren“).
Selbst wenn Sie keine Beispiele haben,
- Ein 1-Shot-Prompt kann schnell mit KI erstellt werden.
- Das Erstellen eines 2-Shot-Prompts erfordert ebenfalls keinen größeren Aufwand als das Schreiben detaillierter Anweisungen (siehe Abschnitt 3.3).
Tatsächlich ist es nicht immer notwendig, ein zweites Beispiel hinzuzufügen. Die Anzahl der Defekte für ein 1-Shot-Prompt könnte sogar niedriger sein als für ein 2-Shot-Prompt. Zum Beispiel produzierte Gemini 1.5 Pro KEINE fehlerhafte Ausgabe bei der Analyse von 3 Protokollen mit meinem 1-Shot-Prompt.
Wenn Sie also einen Entwurf von Anweisungen haben, könnte das Hinzufügen nur eines Beispiels, das aus der ersten KI-Ausgabe mit geringfügigen Anpassungen stammt, die Ergebnisse verbessern. Diese Methode ist weniger komplex als das Verfeinern von Anweisungen innerhalb eines Zero-Shot-Prompts. Darüber hinaus garantiert die Verwendung eines 1-Shot-Prompts mit GPT-4o, GPT-4 oder Gemini fast bessere Qualität im Vergleich zu einem verfeinerten Zero-Shot-Prompt.
Natürlich gelten die genannten Erkenntnisse hauptsächlich für „ausführliche“ Aufgaben, wie die in diesem Artikel behandelte Protokollanalyse. Wenn Sie ein anderes Modellverhalten bei der Bewältigung Ihrer Aufgaben beobachten, teilen Sie Ihre Erfahrungen bitte in den Kommentaren.


