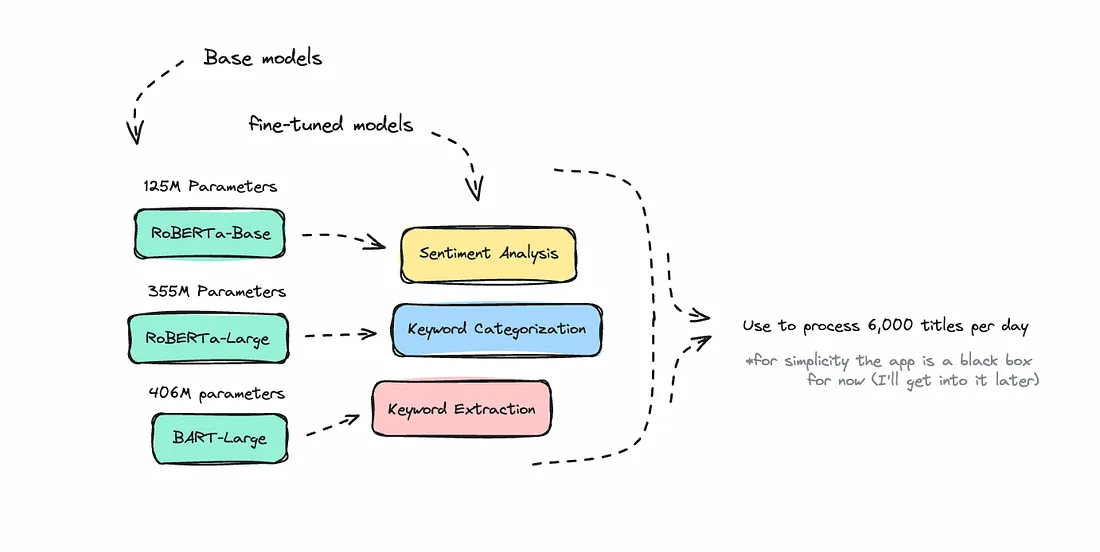
Anhand des Bildes oben können Sie zumindest erahnen, worüber ich sprechen werde: die Verwendung dieser kleineren, feinabgestimmten NLP-Modelle in einer Anwendung. In meinem letzten Artikel ging es um die Feinabstimmung kleinerer natürlichsprachlicher Modelle für spezifische Anwendungsfälle. Konkret habe ich über die Feinabstimmung eines BART-Modells für die Keyword-Extraktion gesprochen. Ich habe es auch open-source gemacht, damit es jeder nutzen kann.
In diesem Artikel jedoch werde ich Ihnen zeigen, wofür ich dieses Modell verwendet habe, sowie zwei weitere kleinere NLP-Modelle. Zwei der Modelle wurden von mir feinabgestimmt, eines habe ich von der Hugging Face Hub bezogen. Wenn ich Leuten die fertige Anwendung zeige, finden sie das Konzept etwas seltsam, wie eine Art Google Trends für den Technologiebereich kombiniert mit einer Suchfunktion.
Die Idee ist, dass die Anwendung bestimmte Technologie-Websites durchsucht und dann mithilfe von NLPs die durchsuchbaren Inhalte analysiert, um die Stimmung zu bestimmen, Keywords zu extrahieren und die Inhalte nach Kategorien zu organisieren.

Beispielprozess für die Verarbeitung von drei Titeln mit drei unterschiedlichen NLP-ModellenDie Ergebnisse ermöglichen es Ihnen, zu sehen, was „im Trend“ ist und in welcher Kategorie oder insgesamt.
Als Beispiel betrachten Sie das folgende Diagramm für die Kategorie Tools.

Wie Sie sehen können, hat Copilot eine schlechte Woche, da die Erwähnungen zunehmen und die Stimmung überwiegend negativ ist.
Die Anwendung ermöglicht es Ihnen auch, die Quellen für die Keywords zu finden, die Sie interessant finden, so dass Sie zu jeder Quelle navigieren oder den Inhalt insgesamt analysieren können. In diesem Fall wäre es interessant, die URLs zu überprüfen, in denen über Copilot gesprochen wird, und zu sehen, was die Leute dazu sagen.
Die Anwendung ist hauptsächlich eine API, aber ich habe letzte Woche auch eine Frontend-Prototyp dafür erstellt. Die Daten werden technisch gesehen nicht im Frontend zwischengespeichert, so dass zu viele Anfragen ein Problem darstellen können. Ich nenne es Safron.
Sie können es ausprobieren; es funktioniert derzeit gut, aber die Daten werden nur einmal täglich aktualisiert. Es wäre möglich, die Daten in Echtzeit zu verarbeiten, aber es wäre auch teurer, die NLP-Modelle 24/7 laufen zu lassen, da sie auf 0 skaliert werden, wenn sie nicht verwendet werden, was die Betriebszeit verringert.
Wie ist es möglich, etwas derartiges zu erstellen, bei dem diese NLP-Modelle den Großteil der Arbeit für mich erledigen? Ich werde eine kurze Einführung in die Anwendung selbst geben und dann auf die technischen Details eingehen.
Es ist zwar keine bahnbrechende Neuheit, aber dennoch interessant, wenn Sie nach Inspiration suchen oder etwas Ähnliches aufbauen möchten.
Einleitung
War es schwer, es zu bauen? Ist es teuer, es zu unterhalten? Warum habe ich es gebaut?
Es war nicht einfach, es zu bauen. Es begann mit einer Idee, und dann, angetrieben von meinem Dickkopf, es durchzuziehen, tat ich es. Bard, die KI, sagte mir, dass es bis zu 6 Monate dauern könnte, etwas derartiges mit 3-5 Entwicklern zu bauen. Ich bin froh, dass ich nicht gefragt habe, bevor ich mich hineingestürzt habe. Ich glaube jedoch, dass Fortschritte in der ML es jetzt möglich machen, etwas derartiges schneller zu erreichen als früher.
Ich wollte etwas derartiges für mich selbst haben. Ich mag es, die öffentliche Meinung und das Verhalten zu analysieren, und da ich im Technologiebereich tätig bin, machte es Sinn. Wenn man etwas aufbaut, verbessert man sich darin, und dann denkt man an neue, innovative Möglichkeiten, damit weiterzuarbeiten. In gewisser Weise braucht man manchmal kein klares Ziel, denn der Prozess selbst produziert etwas Wertvolles.
Wenn Sie Peter Thiel fragen, wäre dies eine hochgradig ineffiziente Art zu arbeiten, wenn Sie sich an sein Konzept der unbestimmten Optimismus, das er sagt, das 21. Jahrhundert plagt. Ich muss meine zukünftigen Unternehmungen möglicherweise überdenken.
Ein Problem, das immer noch etwas lästig ist, ist, dass ich die Skripte morgens manuell überprüfen muss, wenn sie ausgeführt werden. Zu viele Probleme mit der Bereitstellung der NLP-Modelle haben mich davor gewarnt, sie am Wochenende laufen zu lassen. Dies ist zwar ein Problem, aber es ist möglich, diesen Prozess später vollständig zu automatisieren.
Ist es teuer, es zu bauen und zu betreiben?
Der Hauptgrund für die Feinabstimmung dieser kleineren Open-Source-Modelle war, die Kosten niedrig zu halten. Ich bin in meinem letzten Artikel etwas auf die Kosten für die Verwendung von LLMs gegenüber SLMs eingegangen. Wie viel hat also das gesamte Projekt mich gekostet? Weniger als 80 US-Dollar, wenn ich den Kauf der Domainname auslasse.

Dieser Preis beinhaltet die Datenextraktion, die Datenspeicherung, die Hosting, die Feinabstimmung der Open-Source-NLP-Modelle, die API und die Cloud-Hosting. Wenn der Traffic zunimmt, ist das ein separates Problem. Die größten Kosten waren die Verwendung von GPT-4 Turbo, um die initialen Datasets für die kleineren Modelle zu verarbeiten.
Die Frage ist dann, wie teuer wäre etwas derartiges gewesen, wenn ich größere Sprachmodelle verwendet hätte? Die größeren Modelle hätten den Kontext besser verstanden, aber die Kosten für das Aufrufen einer API bis zu 15.000 Mal pro Tag oder das Hosting eines sehr großen Modells wären hoch gewesen. Dies ist jedoch nicht zu sagen, dass effektive kleinere LLMs in der Zukunft nicht gut abschneiden könnten.
Warum habe ich es also gebaut?
Ich habe es angedeutet: Ich wollte einen Hubschrauberblick darüber, was passiert. Man kann mit strukturierten Daten viel erreichen. Sich einfach an Keywords und Kategorien für Produkt- und Community-Forschung zu binden, ist ein Ansatz, aber auch die Möglichkeit, die API zu nutzen, um sie in KI-Agenten einzuspeisen, kann Sie auf dem Laufenden halten, ohne dass Sie täglich viele Texte durchsuchen müssen.
Eine klare Anwendungsmöglichkeit besteht darin, zu sehen, welche KI-Modelle diskutiert werden und in welchem Umfang. Wie oft hören wir, dass ein neues Modell eingeführt wird und es bahnbrechend ist? Durch die Filterung der Daten nach KI-Modellen können Sie die am häufigsten erwähnten KI-Modelle in der Woche identifizieren.

Sortieren der wöchentlichen Daten nach KI-Modelle als KategorieDie Möglichkeit zu sehen, ob die Leute über ein Modell sprechen, kann für mich ausreichen, um es mir anzusehen. Letzte Woche wurden Mistral und Code Llama deutlich häufiger erwähnt als sonst. Der unglaubliche Marktanteil, den ChatGPT hat, ist im Vergleich zu diesen anderen Modellen jedoch beeindruckend. Es lässt einen darüber nachdenken, wie viel Boden es bereits abgedeckt hat.
Um es selbst auszuprobieren, filtern Sie mit der Kategorie nach KI-Modelle & Assistenten. Sie können nach einigen Kategorien wie Unternehmen, Websites, Tools und Plattformen filtern. Ich werde ehrlich sein, das Modell, das diese Kategorisierung für mich durchführt, war ziemlich schwer zu erstellen. Ich musste mich für einen hybriden Ansatz entscheiden, über den ich später sprechen werde.
Eine weitere nützliche Anwendung, die ich entdeckt habe, ist die Verwendung von KI-Agenten mit der API, um die Probleme zusammenzufassen, die die Menschen mit bestimmten Keywords haben. Dies ist großartig für die Erstellung regelmäßiger Berichte, aber auch für die Produktforschung.
Sehen Sie sich ein Beispiel mit den Daten der letzten Woche für das Wort „Copilot“ mit GPT-4 an oder einen Bericht zum Wort „Unity“, den ChatGPT zusammengefasst hat.


Es wäre einfach genug, diese Keywords zu nutzen, indem man die API täglich abfragt, sie von einer LLM verarbeiten lässt und die Berichte dann per E-Mail oder über das bevorzugte Medium versendet.
Bei der Durchsicht dieser Daten habe ich festgestellt, dass es eine Vielzahl von Tools gibt, von denen man nie etwas hört. Wenn man den Trends folgt, stellt man fest, dass die meisten Menschen täglich über die gleichen Tools, Unternehmen und Personen sprechen. Es ist ziemlich selten, dass etwas sofort nach der Einführung in den Mainstream-Track gelangt.
Der Schlüssel wird sein, wenn das System Monate an Daten gesammelt hat, diese Daten zu nutzen, um bessere ML-Prozesse zu schaffen, um zu verstehen, wie und wann etwas an Fahrt gewinnt. Für den Moment funktioniert es jedoch ganz gut, obwohl es von einigen zusätzlichen Datenquellen profitieren könnte, die in es eingespeist werden.
Wie also habe ich es gebaut?
Technischer Prozess
Ich werde nicht ausführlich auf das Web-Crawling oder die Architektur hinter dem Aufbau etwas derartigen eingehen, da es wahrscheinlich bereits jede Menge Inhalte dazu gibt.
Ich speichere Langzeitdaten in BigQuery und hoste zwischengespeicherte Daten in MongoDB. Um die Frontend-API zu erstellen, machte es Sinn, temporäre Sammlungen in MongoDB mit komplexeren SQL-Abfragen in BigQuery auf täglicher Basis durch automatisierte Skripte zu erstellen. Dadurch kann ich die BigQuery-Abfragekosten auf Null reduzieren.
Ich zahle für einen dedizierten MongoDB-Cluster, was eine vorübergehende Lösung ist, da ich die Kosten extrem niedrig halten möchte. Diese Einrichtung ist machbar, aber in diesem Szenario wäre es von Vorteil, die Tabellendaten im Frontend zu zwischenspeichern, um die Anzahl der Anfragen zu reduzieren. Etwas, das ich für den Moment übersprungen habe, da ich ein bisschen Spaghetti-Code habe.
Der Punkt, den ich mit dieser Anwendung machen wollte, war, zu zeigen, dass es praktisch ohne Kosten gemacht werden könnte. Ich denke, ich habe diese Botschaft zumindest teilweise vermittelt.
Lassen Sie uns nun zu den Teilen übergehen, in denen ich Natural Language Processing verwendet habe.
Natural Language Processing
Für alle, die mit Natural Language Processing noch Neuland sind, wurden Transformer-Modelle im Jahr 2017 eingeführt. Diese Modelle vereinfachten die Aufgabe, die Nuancen der natürlichen Sprache für KI-Systeme zu verstehen.
Mit der Veröffentlichung von BERT durch Google im Jahr 2018 wurde die Praxis der Modell-Feinabstimmung üblich. BERT und andere grundlegende Modelle führten das Konzept ein, dass Sie ein vortrainiertes Modell nehmen und es an einem kleineren Dataset für spezifische Aufgaben feinabstimmen können, wobei beeindruckende Ergebnisse erzielt werden.
Erst mit Plattformen wie Hugging Face wurde jedoch die NLP-Technologie zugänglicher, was es mir ermöglichte, die Arbeit, die ich hier vorstelle, durchzuführen und NLP für verschiedene Anwendungsfälle auf einfache Weise einzusetzen. Eines der Modelle, die ich verwende, hat jemand anderes erstellt.
Sentiment, Keyword-Extraktion und Kategorisierung
Unter der Haube wird Safron von einem Trio von NLP-Modellen angetrieben.
Ich wollte ursprünglich sechs Modelle erstellen, aber um meine geistige Gesundheit zu bewahren, habe ich mich auf die Verwendung von drei insgesamt beschränkt.
Das erste Modell, das ich verwende, ist, wenig überraschend, der Tech-Keyword-Extractor. Ich habe in einem früheren Artikel erläutert, wie ich ihn erstellt habe. Seine Bedeutung liegt in seiner Fähigkeit, wichtige Wörter automatisch zu identifizieren, was sonst eine schwierige Aufgabe wäre.
Die Keyword-Extraktion ist eine der Sachen, bei denen die Leute denken, dass sie ganz einfach ist. Wenn man die Leute jedoch fragt, wie sie mit Leerzeichen zwischen den Wörtern umgehen oder wie sie alle notwendigen Füllwörter filtern, um die gewünschten Wörter zu erhalten, lässt sie das etwas nachdenklich zurück. Ohne dieses Modell hätte ich das nicht aufbauen können. Ich werde nicht weiter darauf eingehen, da Sie darüber dort lesen können.
Nachdem ich diesen Keyword-Extractor feinabgestimmt hatte, habe ich ihn noch einmal feinabgestimmt, mit schlechten Ergebnissen. Es lässt mich darüber nachdenken, ob es in der Zukunft Jobs geben wird, die nur der Sortierung von Datasets für Sprachmodelle dienen, so etwas wie die neuen Fließbandarbeiter. Es ist harte Arbeit. GPT-4 kann etwas Hilfe leisten, aber es ist ohne menschliche Aufsicht nicht konsistent genug.
Das zweite Modell, das ich verwendet habe, war der Sentiment-Analysator. Ich habe hier das Modell von jemand anderem verwendet, da es allgemein genug war. Dieses Modell kann einen Text als neutral, positiv oder negativ kategorisieren und ihm eine bestimmte Punktzahl zuweisen. Nachdem ich es nun eine Weile lang verwendet habe, ist es selten, viele positive Texte online zu finden; sie sind in der Regel negativ oder neutral, insbesondere im Technologiebereich.
Aber wie habe ich diese Modelle verwendet? Die Strategie bestand darin, die zuvor verarbeiteten und gespeicherten gesammelten Crawling-Daten zu nehmen und diese beiden Modelle dann täglich in Batches auf die Texte anzuwenden.

Crawlbare Titel werden mit NLPs verarbeitet, um sie in Keywords zu zerlegenDiese Keywords werden dann gespeichert und mit ihrem ursprünglichen Inhalt in einer anderen Datenbanktabelle verknüpft. Ich sammle alle Daten, aggregiere sie und sende sie an MongoDB, von wo aus sie leicht zugänglich sind.
Es ist wichtig anzumerken, dass die Anwendung die Sentiment-Analyse auf Texte als Ganzes anwendet, so dass die Analyse der Keywords kontextbezogen ist. Wenn ein Keyword jedoch konstant eine hohe Menge an negativen Sentiments aufweist, deutet dies normalerweise auf eine negative öffentliche Meinung hin.
Tesla ist eines dieser Unternehmen, die es in letzter Zeit schwer hatten.

Wir können die Tesla-bezogenen Quellen an eine LLM wie ChatGPT senden, um zusammenzufassen, was gesagt wurde, was auf eine negative Sentiment hinweist, die mit dem Keyword verbunden ist.

Ich hätte gerne eine LLM an die Anwendung angehängt, so dass sie Ihnen anstelle der Quellen eine schöne Zusammenfassung gibt. Leider bin ich dafür zu geizig. Sie haben gesehen, wie weit ich gehen werde, um die Kosten auf ein absolutes Minimum zu reduzieren.
Lassen Sie uns jedoch wieder auf Kurs kommen. Ich war noch nicht ganz fertig mit der Extraktion von Keywords und Sentiments, aber ich wollte in der Lage sein, die eintreffenden Wörter zu kategorisieren. Da ich täglich bis zu 5.000 Keywords vor mir hatte, war es zu schwierig, sie zu analysieren. Also machte ich mich daran, ein Encoder-Modell für die Klassifizierung zu feinabzustimmen.
Ich entschied mich für ein größeres RoBERTa-Modell für diese Aufgabe, da ich wollte, dass es an so vielen Daten wie möglich trainiert wird. Das Ziel war, dass es jedes Keyword identifiziert und ihm dann eine Kategorie zuweist.

Ich verwendete einen hybriden Ansatz, der sowohl eine Datenbank als auch das KI-Modell verwendet, um die Kategorie zu bestimmen, obwohl er manchmal Fehler macht. Beispielsweise kategorisierte es „Keto“ letztens fälschlicherweise als Website, was eindeutig etwas daneben ist. Im Allgemeinen funktioniert es gut mit Themen und allgemeinen Wörtern, aber es ist schwierig, da die Leute ihre Sachen „Safron“ und dergleichen nennen.
Trotz dieser Herausforderungen funktioniert es normalerweise gut, obwohl es länger gedauert hat, dieses Modell zu entwickeln als das Keyword-Modell.
Hosting kleinerer NLP-Modelle
Sie können ein kleineres Modell mit Colab starten, aber die Verwendung der kostenlosen Pipeline von Hugging Face, um mit den Modellen zu interagieren, würde etwa 2 Stunden dauern, um bis zu 2.000 Texte mit einem 400M-Parameter-Modell zu verarbeiten.
Ich verarbeite täglich bis zu 6.000 Texte, was bedeutet, dass es jeden Tag etwa 6 Stunden laufen müsste. Das Hosting der Modelle auf einer kleinen GPU ist für diese kleineren Modelle unglaublich effizient; durch die Verwendung einer Nvidia Tesla T4 GPU kann ich 5.000 Texte in 15 Minuten verarbeiten, wobei 20 Texte gleichzeitig bearbeitet werden.
Derzeit habe ich nur die Inference-Endpunkte von Hugging Face zum Hosten dieser Modelle verwendet, hauptsächlich weil sie einfach genug einzurichten waren. Ich zahle 0,60 USD pro Stunde Nutzung, aber die GPU wird auf 0 skaliert, wenn sie nicht verwendet wird, so dass ich im Grunde genommen 0,30 bis 0,60 USD pro Tag bezahle, je nachdem, wie viel Inferenz erforderlich ist.
Ich würde jedoch empfehlen, auch zu lernen, wie man diese Modelle auf anderen Plattformen bereitstellt und hostet, damit man nicht nur von einem Service abhängig ist. Ich habe von Replicate und Modal gehört, dass sie großartig sind. Ihre Preise liegen in etwa auf dem gleichen Niveau.
Letzte Anmerkungen: Es war nicht einfach
Jeder Experte mit Erfahrung auf diesem Gebiet würde wahrscheinlich einen Blick auf dieses Projekt werfen und zugeben, dass es nicht so einfach ist.
Wenn dieser Artikel Sie dazu gebracht hat, zu denken, dass das Erstellen und die Verwendung dieser Modelle einfach ist, dann liegt das an mir. Das Modell für die Extraktion von Tech-Begriffen beispielsweise wird unweigerlich Variationen wie „Google Gemini“ oder „Gemini Pro“ oder „Googles Gemini“ extrahieren. Die Bereinigung danach ist schwierig. Sie können diesen kleineren Modellen keine Anweisungen geben; sie funktionieren auf der Grundlage der Daten, an denen sie trainiert wurden. Sie benötigen eine zusätzliche Verarbeitung, um die Wörter richtig zu verbinden, und selbst dann werden einige verloren gehen. Oder Sie gehen zurück und trainieren es erneut, was viel Arbeit ist.
Das Kategorisierungsmodell wurde mit RoBERTA erstellt, das zuletzt 2019 trainiert wurde. Es hat viele dieser Tools und Unternehmen, die es kategorisieren soll, nicht gesehen. Es wird Vermutungen über die richtige Kategorie anstellen, aber Sie benötigen eine große Menge an Daten, um es darin zu trainieren. Schließlich verwendete ich eine hybride Methode, die die Kategorien für die Keywords speichert, die einfach angepasst und erneut verwendet werden können, um das Modell weiter zu feinabzustimmen.
Ein weiteres häufiges Problem war, dass viele Faktoren ein Sprachmodell stören können, was ich im Laufe der Zeit herausgefunden habe. Beispielsweise stürzte mein gehostetes Modell die GPU ab, wenn ein chinesisches Zeichen einschlich, einfach weil es diese Art von Sprache noch nicht gesehen hatte. Die Fehlerbehebung dauerte 6 Stunden. Wenn man das Modell selbst erstellt, versteht man zumindest die zugrunde liegenden Daten, mit denen es erstellt wurde, und kann lernen, effektiv damit zu arbeiten.
Wir sind noch nicht an dem Punkt, an dem wir diese Modelle ohne technische Fähigkeiten feinabstimmen können, und die Bibliotheken, die verwendet werden, um den Prozess zu vereinfachen, können Fehler einführen, die nicht sofort offensichtlich sind. Die von mir erstellten Modelle funktionieren jedoch derzeit gut, so dass wir ziemlich weit gekommen sind.
Manchmal muss man etwas einfach nur beenden, um die Erfahrung des Beendens etwas zu machen. Dies bringt einen in neues Terrain.
Ich bin ziemlich begierig darauf, die Daten zu analysieren und Wege zu finden, wie ich sie effektiv nutzen kann. Ich werde sehen, ob ich Zeit habe, eine monatliche und eine quartalsweise Ansicht einzurichten.
Sie sind eingeladen, die Anwendung zu nutzen, aber ich muss möglicherweise die API-Aufrufe begrenzen, wenn die Leute sie übermäßig nutzen.
❤