Einführung
Wie üblich half ich meiner Tochter am Wochenende bei ihren Chinesisch-Hausaufgaben. Dabei stieß ich auf ein Gedicht, das die Entwicklung des Generative AI Agenten wunderschön widerspiegelt. Das Gedicht mit dem Titel „人有两件宝“ oder „Jeder Mensch hat zwei Schätze“ beschreibt die Essenz des Large Language Model Agent Konzepts. Es besagt, dass jeder Mensch zwei Schätze besitzt: unsere Hände und unser Gehirn.
Unsere Hände stehen für die Fähigkeit zu handeln, Werkzeuge zu benutzen, Gegenstände zu bewegen und zu erschaffen. Unser Gehirn symbolisiert die Fähigkeit zum Denken, zur Planung, zur Reflexion und zur Erinnerung.
Die Kombination aus Handeln und Denken ist grundlegend für die Generative AI Agenten Technologien, ähnlich wie die Verwendung von Händen und Gehirn im chinesischen Gedicht:
„Wenn Hände allein eine Aufgabe erledigen, ohne ein wenig Nachdenken, ist es zu viel verlangt. Und das Gehirn allein, wenn es alles ist, was wir benutzen, ohne unsere Hände, wozu sind dann Hinweise gut? Aber benutzt man beides zusammen, stark und im Einklang, kann nichts schiefgehen. Mit Händen und Gehirn, Seite an Seite, gibt es nichts, was wir nicht mit Stolz tun können!“

In diesem Artikel werden wir die Grundkonzepte der Agenten Technologien diskutieren. Wir werden untersuchen, wie sie planen, Werkzeuge nutzen, Erinnerungen speichern und in Multi-Agenten-Systemen zusammenarbeiten, um ihre Fähigkeiten zu verbessern. Wenn wir diese Elemente verstehen, können wir erkennen, wie Agentenbasierte Systeme die Grenzen dessen verschieben, was in der KI möglich ist.
Übersicht über das Agenten-Framework
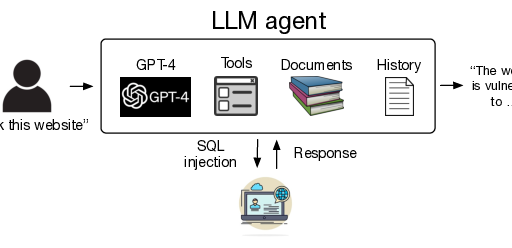
Das Agenten-Framework besteht aus Planung, Werkzeugen und Erinnerung. Jeder dieser Aspekte spielt eine entscheidende Rolle bei der Funktionsweise und dem Erfolg des Agenten.

Planung
Die Planung ist ein strategischer Aspekt für Agenten. Dabei bestimmen sie die Schritte, die notwendig sind, um ein Ziel zu erreichen. Es gibt verschiedene Techniken:
Reflexion: Agenten denken über das Feedback nach, das sie von Aufgaben erhalten, und schreiben ihre Episodenerinnerung auf, um ihnen bei der Entscheidungsfindung in den nächsten Schritten zu helfen. Dies ist ein Selbstverbesserungsmechanismus innerhalb des Agenten, der es ihm ermöglicht, aus vergangenen Aktionen zu lernen, über die Ergebnisse nachzudenken und bessere Entscheidungen in zukünftigen Aufgaben zu treffen.

Denkprozess: Wir können die Prompting-Technik nutzen, um das Large Language Model zu veranlassen, einen Schritt-für-Schritt-Denkprozess aufzubauen, der einer menschlichen Denkweise ähnelt, um eine Schlussfolgerung oder Antwort zu erreichen.
Neuere wissenschaftliche Arbeiten wie „Tree of Thoughts“ und „Algorithm of Thoughts“ haben vorgeschlagen, dass Prompting-Strategien, die auf baum- oder graphenbasierten Datenstrukturen für das Kontextmanagement basieren, die Anzahl der erforderlichen Prompts reduzieren können.

Zerlegung: Der Agent kann komplexe Probleme in kleinere, verwaltbare Teile zerlegen. Von dort aus können wir verschiedene Werkzeuge einsetzen, um modulare Probleme zu lösen.
ReAct: Dieser Prozess kombiniert Reflexion (Denken) und Aktion (Handeln), was es dem Agenten ermöglicht, iterativ zu denken, zu handeln und zu beobachten, um komplexe Aufgaben dynamisch zu lösen.
Dieses Konzept wird im Paper „ReAct: Synergizing Reasoning and Acting in Language Models“ erläutert und wird bereits von LangChain und LlamaIndex in ihrem Agenten-Framework umgesetzt.
Werkzeuge
Sobald wir einen Plan haben, um Probleme zu lösen, sind Werkzeuge die funktionalen Aspekte, die es den Agenten ermöglichen, diese Pläne umzusetzen.
Abruf / RAG: RAG steht für „Retrieval Augmented Generation“. Dabei wird die Antwort des Agenten durch die Integration externer Daten, beispielsweise aus einem Vektor-Speicher oder einem großen Datenkorpus, verbessert.

Suchwerkzeuge: Verschiedene Dienste können von Agenten genutzt werden, um Informationen zu finden und zu navigieren, was ihnen bei der Entscheidungsfindung hilft. Beispiele hierfür sind Wikipedia, Tavily und andere.
Code-Interpreter: Externe Werkzeuge, die es den Agenten ermöglichen, Code besser zu verstehen und auszuführen, was für die Entwicklung von Generative AI Anwendungen wichtig ist.
Mathematische Werkzeuge: Werkzeuge, die speziell für mathematische Berechnungen entwickelt wurden.
Benutzerdefinierte Werkzeuge: Wir können auch jede externe Funktion oder API-Endpunkt in benutzerdefinierte Werkzeuge integrieren, was den Agenten eine Vielzahl von Möglichkeiten bietet.

Erinnerung
Die Erinnerung des Agenten umfasst zwei Kategorien: die kurzfristige und die langfristige Erinnerung.
Kurzfristige Erinnerung: Die Fähigkeit des Agenten, Informationen temporär zu speichern und zu verarbeiten, wenn sie für die Ausführung einer Aufgabe benötigt werden.
Langfristige Erinnerung: Die Fähigkeit, Informationen auch nach dem Ende einer Konversation zu speichern und abzurufen. Dabei wird oft eine externe Datenbank verwendet, um das Wissen des Agenten zu erweitern.
Semantisches oder Standard-Cache: Als Erweiterung der langfristigen Erinnerung kann es auch hilfreich sein, die Paare von Anweisungen und Antworten des Large Language Model in einer Datenbank, einem Vektor-Speicher oder einer Datenbank mit Vektor-Fähigkeiten zu speichern. Bevor die nächste Anfrage an das Large Language Model gesendet wird, kann der Agent das Cache überprüfen, um die Antwortzeit zu beschleunigen und die Kosten für den API-Aufruf zu reduzieren.
Implementierung von Agenten mit Beschleunigern
Da die Menschen erkannt haben, dass Agenten die Zukunft der Generative AI sind, haben viele technische Stacks und Cloud-Anbieter ihre eigene Methode zur Erstellung von KI-Agenten entwickelt. In diesem Abschnitt werden wir einige der wichtigsten technischen Stacks und ihre Ansätze vorstellen.
Agenten mit LangChain
Planung und Ausführung mit AgentExecutor: Auf der Ausführungsebene bietet LangChain den AgentExecutor, der das „Gehirn“ des Agenten – das Sprachmodell und die Werkzeuge, die es nutzen kann – in eine kohärente Laufzeitumgebung einbindet.
Hier entscheidet der Agent über Aktionen, die der AgentExecutor dann ausführt. Diese Trennung von Entscheidungsfindung und Ausführung entspricht einem bewährten Entwurfsmuster in der Softwareentwicklung und verbessert die Wartbarkeit und Skalierbarkeit.
Definition von Agenten-Werkzeugen mit LangChain: Die Erstellung von Agenten-Werkzeugen ist ein zentraler Teil der Funktionalität von LangChain. Dabei werden über 60 Werkzeuge integriert, wie beispielsweise Wikipedia-Suche, YouTube, Yahoo-Suche, Google Scholar und andere, die Sie direkt in Ihrer KI-Anwendung nutzen können.
Zusätzlich zu den integrierten Werkzeugen mit LangChain können Sie auch Ihre eigenen Werkzeuge erstellen. Ein Beispiel hierfür ist die Erstellung von Abrufwerkzeugen aus Ihrer operativen Datenbank, um Ihren Produktkatalog zu erhalten.
Einbeziehung von Erinnerung: LangChain adressiert auch die Herausforderung der Agenten-Erinnerung. Obwohl es sich noch in der Beta-Phase befindet, bietet LangChain Mechanismen, um die Chat-Historie in die Erinnerung des Agenten einzubeziehen. Dadurch werden die Agenten in der Lage, staatliche Interaktionen durchzuführen, sich an vorherige Austausche zu erinnern und diese zu nutzen. Diese Fähigkeit ist entscheidend, um Kontinuität und Kontext in Konversationen oder Aufgabensequenzen zu bieten und eine menschlichere Interaktion mit den Nutzern zu ermöglichen.
Agenten-Typen: In LangChain werden die Agenten-Typen auf der Grundlage des beabsichtigten Modelltyps, der Unterstützung von Chat-Historie, der Fähigkeit, mehrere Eingabe-Werkzeuge zu handhaben, und der parallelen Funktionsaufrufe kategorisiert. Einige Beispiele hierfür sind ReAct Agent, Self Ask with Search Agent und Tool Calling Agent.
Die Wahl des Agenten-Typs sollte auf den Fähigkeiten des Modells und der Komplexität der beabsichtigten Aufgaben basieren.
Praktisches Beispiel für die Erstellung eines Agenten mit LangChain: Dieser Code richtet einen benutzerdefinierten Agenten ein, der in der Lage ist, Aufgaben auszuführen und den Konversationszustand über mehrere Interaktionen hinweg aufrechtzuerhalten. Er kombiniert die Werkzeugbindung, die Prompt-Vorlagen, das Erinnerungsmanagement und die Executor-Logik in eine umfassende Einrichtung für ein konversationsfähiges KI-Modell, das die OpenAI-APIs nutzt. Dieses Beispiel kann als Grundlage für die Entwicklung von fortgeschritteneren Agenten dienen, die auf spezifische Anwendungsfälle zugeschnitten sind. (Bitte beachten Sie, dass dieser Code möglicherweise nicht mehr aktuell ist und Sie sich auf die offizielle Dokumentation von LangChain beziehen sollten, um die neueste Version zu erhalten.)
from langchain_openai import ChatOpenAI
from langchain.agents import tool
# Load the language model
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# Define a simple tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
# Example tool invocation
get_word_length.invoke("abc")
tools = [get_word_length]
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# Create the prompt template
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are very powerful assistant, but don't know current events"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
# Bind tools to the LLM
llm_with_tools = llm.bind_tools(tools)
from langchain.agents.format_scratchpad.openai_tools import format_to_openai_tool_messages
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
# Create the agent
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
from langchain.agents import AgentExecutor
# Initialize the agent executor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# Example of using the agent
print(list(agent_executor.stream({"input": "How many letters in the word educa"})))
# Adding memory to the agent
MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are very powerful assistant, but bad at calculating lengths of words."),
MessagesPlaceholder(variable_name=MEMORY_KEY),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
from langchain_core.messages import AIMessage, HumanMessage
# Setting up memory tracking
chat_history = []
# Updated agent with memory
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
"chat_history": lambda x: x["chat_history"],
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# Running the agent with memory
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend(
[
HumanMessage(content=input1),
AIMessage(content=result["output"]),
]
)
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Agenten mit LlamaIndex
Datenagenten, die von LlamaIndex unterstützt und durch LLM (Large Language Models) verbessert werden, sind sehr ähnlich zu dem, was wir im vorherigen Abschnitt besprochen haben. Es gibt drei Hauptkomponenten:

Planung: Die „Agent Reasoning Loop“ Logik ist hier von zentraler Bedeutung. Wenn der Agent eine neue Nachricht von einem Nutzer erhält, nutzt der Agent die „Reasoning Loop“, um zu entscheiden, ob er die Erinnerung abrufen sollte, welche Werkzeuge er nutzen sollte, in welcher Reihenfolge und mit welchen Parametern er jedes Werkzeug aufrufen sollte.
Die Reasoning Loop ist das Herzstück der Funktionsweise des Agenten. Es werden verschiedene Agenten-Typen unterstützt, darunter:
- Function Calling Agents: Diese funktionieren gut mit Function-Calling LLMs.
- ReAct Agent: Dieser ist für Chat-/Text-Completion-Endpunkte geeignet.
- Fortgeschrittene Agenten: Dazu gehören LLMCompiler, Chain-of-Abstraction, Language Agent Tree Search und andere.
Werkzeuge: Dem Agenten wird eine Reihe von Werkzeugen zur Verfügung gestellt, aus denen er wählen kann, welches er nutzen möchte. Auf der Grundlage der aktuellen Abfrage und der Konversationshistorie entscheidet der Agent, welche Werkzeuge er einsetzen sollte. Diese können RAG für die Informationsabfrage, spezifische Suchwerkzeuge oder andere maßgeschneiderte Funktionen umfassen.
Die ausgewählten Werkzeuge verarbeiten die Eingabe und generieren Ausgaben, die Abfrageergebnisse, berechnete Werte oder zu ergreifende Aktionen umfassen können.
Erinnerung: Der Agent ruft die Konversationshistorie aus der Erinnerung ab, um sicherzustellen, dass seine Antworten in einem Zusammenhang stehen und auf der vorherigen Konversation aufbauen. Nach der Verarbeitung aktualisiert der Agent die Konversationshistorie in der Erinnerung für zukünftige Referenzen, um den Fluss der Interaktion aufrechtzuerhalten.
Datenagenten in LlamaIndex ermöglichen es, Nutzerabfragen End-to-End durch eine benutzerfreundliche Schnittstelle auszuführen. Es werden auch niedrigschwellige APIs für eine schrittweise Ausführung angeboten, die eine feine Kontrolle über den Fortschritt und die Analyse von Aufgaben ermöglichen.
Ein Datenagent kann beispielsweise durch die Instanziierung aus einem Satz von Werkzeugen erstellt und betrieben werden. Ein ReAct-Agent kann beispielsweise mit verschiedenen Werkzeugen erstellt werden, um sowohl Chat- als auch Abfragefunktionen zu unterstützen. Diese Agenten erben auch von ChatEngine und QueryEngine, die zusätzliche Funktionen bieten können.
Beispiel für die Implementierung eines Datenagenten in LlamaIndex: In diesem Kochbuch wird ein Beispiel für die Erstellung eines benutzerdefinierten OpenAI-Agenten in Python gezeigt, der die OpenAI-API mit Funktionsaufruf-Fähigkeiten nutzt. Es werden die Erstellung von Werkzeugen, die Einrichtung des Agenten und die Interaktion mit dem Agenten in einem konversationsbasierten Kontext gezeigt.
import json
from typing import Sequence, List
from llama_index.llms.openai import OpenAI
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
from openai.types.chat import ChatCompletionMessageToolCall
import nest_asyncio
# Apply necessary async adjustments
nest_asyncio.apply()
# Define computational tools for the agent
def multiply(a: int, b: int) -> int:
"""Multiply two integers and return the result"""
return a * b
def add(a: int, b: int) -> int:
"""Add two integers and return the result"""
return a + b
# Create FunctionTool instances from defined functions
multiply_tool = FunctionTool.from_defaults(fn=multiply)
add_tool = FunctionTool.from_defaults(fn=add)
# Define the custom OpenAI agent class
class YourOpenAIAgent:
def __init__(self, tools: Sequence[BaseTool] = [], llm: OpenAI = OpenAI(temperature=0, model="gpt-3.5-turbo-0613"), chat_history: List[ChatMessage] = []) -> None:
self._llm = llm
self._tools = {tool.metadata.name: tool for tool in tools}
self._chat_history = chat_history
def reset(self) -> None:
"""Reset the conversation history"""
self._chat_history = []
def chat(self, message: str) -> str:
"""Process a message through the agent, managing tool invocations and responses"""
self._chat_history.append(ChatMessage(role="user", content=message))
tools = [tool.metadata.to_openai_tool() for _, tool in self._tools.items()]
ai_message = self._llm.chat(self._chat_history, tools=tools).message
self._chat_history.append(ai_message)
# Handle parallel function calling
tool_calls = ai_message.additional_kwargs.get("tool_calls", [])
for tool_call in tool_calls:
function_message = self._call_function(tool_call)
self._chat_history.append(function_message)
ai_message = self._llm.chat(self._chat_history).message
self._chat_history.append(ai_message)
return ai_message.content
def _call_function(self, tool_call: ChatCompletionMessageToolCall) -> ChatMessage:
"""Invoke a function based on a tool call"""
tool = self._tools[tool_call.function.name]
output = tool(**json.loads(tool_call.function.arguments))
return ChatMessage(name=tool_call.function.name, content=str(output), role="tool", additional_kwargs={"tool_call_id": tool_call.id, "name": tool_call.function.name})
# Create and test the agent
agent = YourOpenAIAgent(tools=[multiply_tool, add_tool])
print(agent.chat("Hi")) # Expected response: Greeting or prompt from the model
print(agent.chat("What is 2123 * 215123")) # Expected response: Result of multiplication
Agenten mit AWS Bedrock
Hier ist der Ablauf eines Agenten innerhalb von AWS Bedrock. Der Prozess ist in zwei Hauptteile unterteilt: die anfängliche Verarbeitung der Nutzer-Eingabe und die Kern-Aktions-Schleife:

Verarbeitung der Nutzer-Eingabe: Wenn der Agent eine Eingabe von einem Nutzer erhält, überprüft er die Prompt-Speicherung, um erweiterte Prompts abzurufen, und die Sitzungsspeicherung, um die Konversationshistorie abzurufen. Das Grundlagen-Modell, das ein großes Sprachmodell sein kann, wird dann aufgerufen, um den Prompt vorzuverarbeiten und seine Gültigkeit zu bestimmen und das Verständnis der Absicht des Nutzers zu verbessern.
Kern-Aktions-Schleife: Das Grundlagen-Modell wird erneut aufgerufen, diesmal jedoch, um den Prompt zu orchestrieren und einen Aktionsplan zu erstellen, der auf den zuvor abgerufenen Prompts und der Historie basiert. Die Antwort wird dann analysiert und auf der Grundlage dieser Entscheidung der Agent entweder eine Aktion auslösen oder zusätzliche Dokumente aus der Wissensbasis abrufen, um seine Antwort zu informieren.
Wenn eine Aktion ausgelöst wird, kann die Aktions-Gruppen-Lambda-Funktion aufgerufen werden, um die Aktion auszuführen und eine Beobachtung zu generieren, die zu einem RAG-/Dokumentenabruf führen kann. Diese Schleife wird fortgesetzt – mit dem Aufruf des Modells, dem Analysieren von Antworten, dem Auslösen von Aktionen und dem Generieren von Beobachtungen – bis der Agent entweder die Aufgabe abgeschlossen hat oder den Nutzer um weitere Informationen bittet.

Erstellung eines Agenten in AWS: Agenten in AWS Bedrock bestehen aus mehreren Hauptkomponenten:
- Grundlagen-Modell (FM): Ein ausgewähltes KI-Modell, das die Eingabe des Nutzers interpretiert und den Antwort-Fluss orchestriert.
- Anweisungen und erweiterte Prompts: Detaillierte Anweisungen, die den Agenten bei seinen Aktionen und seiner Logik anleiten.
- Aktions-Gruppen: Optionale Komponenten, die ein OpenAPI-Schema und AWS Lambda-Funktionen enthalten, die die API-Operationen definieren, die der Agent ausführen kann, um Aufgaben zu erledigen.
- Wissensbasen: Optionale Komponenten, die dem Agenten Kontext bieten und die Abfrageergebnisse verbessern. Es werden mehrere Vektor-Datenbanken unterstützt, darunter OpenSearch, Redis, Pinecone und Amazon Aurora.
Im Folgenden finden Sie einige Screenshots, die Ihnen einen allgemeinen Überblick über die Erstellung dieser Komponenten in AWS geben:


Agenten mit Gemini
Seit April 2024 bietet Google den Vertex AI Agent Builder an. Der Agent Builder ist ein Tool, das die Erstellung von KI-Agenten mit GCP beschleunigen soll.
Auf der Benutzeroberfläche können wir einfach den Agenten definieren, das Ziel, das der Agent erreichen soll, Anweisungen bereitstellen und konversationsbasierte Beispiele teilen.


Durch den Agent Builder können wir auch Unternehmensdaten nutzen, die in GCP gespeichert sind, um das Modell zu verbessern. Wir können Funktionen aufrufen und uns mit Anwendungen verbinden, um Aufgaben für den Nutzer auszuführen.


Multi-Agenten-Framework
Das Feld der KI-Agenten befindet sich noch in seinen Anfängen. Jedes Framework oder jeder Entwicklungs-Stack hat seine eigene Methode zur Erstellung von Einzel-Agenten. Es hat sich jedoch schnell gezeigt, dass Agenten, die zusammenarbeiten, ihre Funktionalität verbessern und das Spektrum ihrer Anwendungen erweitern können. Die Zusammenarbeit von Agenten stellt jedoch zwei Haupt-Herausforderungen dar:
- Die Orchestrierung von Workflows, die mehrere Agenten umfassen
- Die Schwierigkeit, die Kommunikation zwischen Agenten zu etablieren, da sie oft unterschiedliche Schnittstellen nutzen
Microsoft AutoGen
Um die Herausforderung der Agenten-Orchestrierung anzugehen, hat Microsoft im Oktober 2023 das AutoGen-Framework vorgestellt. AutoGen ist darauf ausgelegt, die Entwicklung von Multi-Agenten-Anwendungen zu vereinfachen, insbesondere bei der Orchestrierung von LLM-Agenten.
AutoGen bietet ein Multi-Agenten-Konversations-Framework als eine High-Level-Abstraktion. Es ist eine Open-Source-Bibliothek, die die Entwicklung der nächsten Generation von LLM-Anwendungen mit Multi-Agenten-Kollaborationen ermöglicht.
Mit AutoGen können wir Agenten mit unterschiedlichen großen Sprachmodellen erstellen. Wir können beispielsweise einen Agenten für die Code-Generierung und -Ausführung und einen Agenten für das menschliche Feedback und die Einbindung erstellen.
Ein praktisches Beispiel: Ein Nutzer, der daran interessiert ist, Chinesisch zu lernen. Über AutoGen können wir drei Agenten einsetzen – einen, der mit dem Nutzer interagiert, einen, der den Kurs plant, und einen, der Kursinhalte vorschlägt. Der Nutzer interagiert mit dem Nutzer-Proxy-Agenten, der ihm die Möglichkeit gibt, den Kursplan zu validieren. Der Lehr-Agent nutzt dann die Wissensdatenbank, um Lernmaterialien zu finden und einen Tag-für-Tag-Kurs auf der Grundlage der Nutzer-Präferenzen zu erstellen.

Wenn Sie mehr über AutoGen erfahren möchten, können Sie sich meinen vorherigen Artikel „AutoGen In-depth yet Simple: Revolutionizing AI Collaboration for Excellence in Enterprise“ ansehen oder den Artikel „No Code GenAI Agents Workflow Orchestration: AutoGen Studio with Local Mistral AI Model“.
crewAI
Das crewAI-System ist darauf ausgelegt, die dynamische und kollaborative Natur der Teamarbeit von Menschen nachzuahmen, bei der die einzigartigen Fähigkeiten und Attribute jedes Teammitglieds zur Erreichung eines gemeinsamen Ziels beitragen. Es bringt Effizienz und Struktur in die von KI gesteuerte Aufgabenausführung.
Das crewAI-Framework wird wie folgt aufgebaut:
- Agenten: Sie werden mit spezifischen Attributen und Fähigkeiten initialisiert.
- Aufgaben: Sie enthalten eine detaillierte Beschreibung der Ziele und der erwarteten Ergebnisse.
- Werkzeuge: Die Werkzeugkiste der Agenten ermöglicht es ihnen, verschiedene Aktionen effektiv auszuführen.
- Prozesse: Sie diktieren die strategische Vorgehensweise der Crew bei der Erledigung von Aufgaben.

Beispiel für die Implementierung mit crewAI: In diesem Beispiel gibt es vier Schritte:
- Definition der Agenten: Es werden zwei Agenten konfiguriert, ein Forscher und ein Autor, mit spezifischen Rollen, Verbose-Modus, Erinnerung und einer Hintergrundgeschichte, die ihre Interaktionen leitet.
- Definition der Aufgaben: Es werden spezifische Aufgaben für die Agenten definiert, mit detaillierten Zielen und erwarteten Ausgaben, sowie Aufgaben-bezogenen Konfigurationen wie asynchrone Ausführung und Ausgabe-Datei-Spezifikationen.
- Bildung der Crew: Die Agenten werden zu einer Crew kombiniert, mit definierten Prozessen und erweiterten Konfigurationen wie Erinnerungs-Nutzung und Aufgaben-Sharing.
- Ausführung: Die Ausführung wird gestartet, wobei Eingabe-Variablen in das System eingespeist werden, um einen personalisierten Ansatz zu ermöglichen, und das Ergebnis der kollaborativen Bemühungen der Crew wird gedruckt.
Hier ist der Code-Schnipsel für die Umsetzung:
# Required installations
!pip install crewai
!pip install 'crewai[tools]'
# Set up environment variables
os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API key
os.environ["OPENAI_API_KEY"] = "Your Key"
# Define agents with distinct roles and capabilities
search_tool = SerperDevTool()
researcher = Agent(
role='Senior Researcher',
goal='Uncover groundbreaking technologies in {topic}',
verbose=True,
memory=True,
backstory=("Driven by curiosity, you're at the forefront of innovation, eager to explore and share knowledge that could change the world."),
tools=[search_tool],
allow_delegation=True
)
writer = Agent(
role='Writer',
goal='Narrate compelling tech stories about {topic}',
verbose=True,
memory=True,
backstory=("With a flair for simplifying complex topics, you craft engaging narratives that captivate and educate, bringing new discoveries to light in an accessible manner."),
tools=[search_tool],
allow_delegation=False
)
# Define tasks with specific objectives
research_task = Task(
description=("Identify the next big trend in {topic}. Focus on identifying pros and cons and the overall narrative. Your final report should clearly articulate the key points, its market opportunities, and potential risks."),
expected_output='A comprehensive 3 paragraphs long report on the latest AI trends.',
tools=[search_tool],
agent=researcher,
)
write_task = Task(
description=("Compose an insightful article on {topic}. Focus on the latest trends and how it's impacting the industry. This article should be easy to understand, engaging, and positive."),
expected_output='A 4 paragraph article on {topic} advancements formatted as markdown.',
tools=[search_tool],
agent=writer,
async_execution=False,
output_file='new-blog-post.md'
)
# Form a crew with configured agents and tasks
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential, # Sequential task execution is default
memory=True,
cache=True,
max_rpm=100,
share_crew=True
)
# Kick off the task execution process
result = crew.kickoff(inputs={'topic': 'AI in healthcare'})
print(result)
Agenten-Protokoll
Das Agenten-Protokoll wurde entwickelt, um eine einheitliche Schnittstelle für die Kommunikation mit verschiedenen Agenten bereitzustellen und die zweite Herausforderung bei der Zusammenarbeit von Multi-Agenten-Systemen anzugehen. Jeder Agenten-Entwickler kann dieses Protokoll implementieren.
Das Agenten-Protokoll ist eine API-Spezifikation – eine Liste von Endpunkten, die der Agent bereitstellen muss, mit vordefinierten Antwortmodellen. Das Protokoll ist technologie-agnostisch. Jeder Agent kann dieses Protokoll nutzen, unabhängig davon, welches Framework er verwendet (oder nicht verwendet).
Wie funktioniert das Protokoll? Das Protokoll ist derzeit als REST-API (über die OpenAPI-Spezifikation) mit zwei wesentlichen Routen für die Interaktion mit Ihrem Agenten definiert:
POST /ap/v1/agent/taskszur Erstellung einer neuen Aufgabe für den Agenten (z. B. um ein Ziel zu definieren, das Sie erreichen möchten)POST /ap/v1/agent/tasks/{task_id}/stepszur Ausführung eines Schritts der definierten Aufgabe
Es gibt auch einige zusätzliche Routen zum Auflisten von Aufgaben, Schritten und zum Herunterladen/Hochladen von Artefakten.
Hier ist das GitHub-Repository des Agenten-Protokolls, wenn Sie mehr erfahren möchten.
Fazit
Die Zukunft von Generative AI ist aufregend. Die Fähigkeit zur Planung, zur Nutzung von Werkzeugen und zur Erinnerung wird es Agenten ermöglichen, noch leistungsfähiger zu werden und mit LLM zusammenzuarbeiten. Agenten aus Systemen wie LangChain, LlamaIndex, AWS, Gemini, Microsoft AutoGen und crewAI verändern die Technologie und ermöglichen es uns, KI-Systeme zu schaffen, die „Hände und Gehirn“ haben und uns bei dem unterstützen, was wir jeden Tag tun.